It is possible to run Process Services in “multi-schema multi-tenancy” mode (MS-MT). This is a multi-tenant setup where every tenant has its own database schema. This means that the data of one tenant is completely separated from the data of other tenants.
This is an alternative to the “regular” multi-tenant mode, where the data of all tenants is stored in the same database schema and the data gets a “tenant tag” to identity which tenant the data belongs to. The following diagram shows this setup:

The main benefit of this setup is the ease of setup and configuration: there is no difference with setting up a single-tenant or multi-tenant. Each request can be handled by any node and the loadbalancer simply can route using simple routing algorithms.
The downside of this setup is clearly that the database can become the bottleneck if it has to hold all the data of all tenants and there is no “physical separation” of the tenant data.
The MS-MT setup looks as follows:

The most important benefit of this approach is that the data of each tenant is completely separated from the data of other tenants. Since only data of one tenant is stored in the database schema, queries will generally be more performant.
The downside of this approach is immediately visible in this diagram: each node needs to have a connection pool to the database schema of the tenant. With many tenants, this can mean quite a bit of “housekeeping” that will need to be performed compared to the previous approach (which can be negative for performance). Note that there is a “master database” or “primary database” in this diagram. This database stores the configurations of the tenant data sources and the mapping between user and tenant.
Alternatively, as shown in the following diagram, it is possible to configure the Suite nodes as such that they only manage a certain list of tenants (for example in the picture below the last node only manages tenant Z, and the first two manage tenant A and B, but not Z). Although this alleviates the downside of the previous setup, it does come with an extra cost: the load balancer now needs to be more intelligent and needs to route the incoming request to the appropriate node. This means that the request needs information to differentiate as to which tenant the request is coming from. This needs custom coding on the client side and is not by default available in the Process Services web client.

Taking this to the extreme, it is possible to have one (or more nodes) for one tenant. However, in that case it is probably easier to run a single tenant Process Services for each tenant. The remarks about the load balancer and enriching the request with tenant information as in the previous setup still apply.
Limitations
Currently, following known limitations apply to the multi-schema multi-tenancy (MS-MT) feature:
- As with regular multi-tenancy, it is not possible to configure the out of the box LDAP synchronization to synchronize users to different tenants.
- The tenant can only be configured through the REST API, not via the “identity management” app.
- Users need to be created by a user that is a “Tenant Administrator”, not a “Tenant Manager”.
- Updating a tenant configuration (more specifically: switching the data source) cannot be done dynamically, a restart of all nodes is required for it to be picked up.
- A user id needs to be unique across all tenants (cft. an email). This is because a mapping {user id, tenant id} will be stored in the primary database to determine the correct tenant data source.
Implementation
This section describes how the MS-MT feature works and can be skipped if only interested in setting up an MS-MT Process Services.
The MS-MT feature depends on this fundamental architecture:
- There is one primary datasource
- The configurations of the tenants is stored here (for example their data source configuration).
- The user to tenant mapping is stored here (although this can be replaced by custom logic).
- The “Tenant Manager” user is stored here (as this user doesn’t belong to any tenant).
- There are x data sources
- The tenant specific data is stored here.
- For each tenant, a datasource configuration similar to a single tenant datasource configuration needs to be provided.
- For each tenant datasource, a connection pool is created.
- When a request comes in, the tenant is determined.
- A tenant identifier is set to a threadlocal (making it available for all subsequent logic executed next by that thread).
- The
com.activiti.database.TenantAwareDataSourceswitched to the correct tenant datasource based on this threadlocal.
The following diagram visualizes the above points: when a request comes in, the security classes for authentication (configured using Spring Security) will kick in before executing any logic. The request contains the userId. Using this userId, the primary datasource is consulted to find the tenantId that corresponds with it (note: this information is cached in a configurable way so the primary datasource is not hit on every request. But it does mean that user removals from a tenant can take a configurable amount of time to be visible on all nodes). This does mean that in MS-MT mode, there is a (very small) overhead on each request which isn’t there in the default mode.
The tenantId is now set on a threadlocal variable (mimicking how Spring Security and its SecurityContext works). If the value is ever needed, it can be retrieved through the com.activiti.security.SecurityUtils.getCurrentTenantId() method.
When the logic is now executed, it will typically start a new database transaction. In MS-MT mode, the default DataSource implementation is replaced by the com.activiti.database.TenantAwareDataSource class. This implementation returns the datasource corresponding with the tenantId value set on the threadlocal. The logic itself remains unchanged.
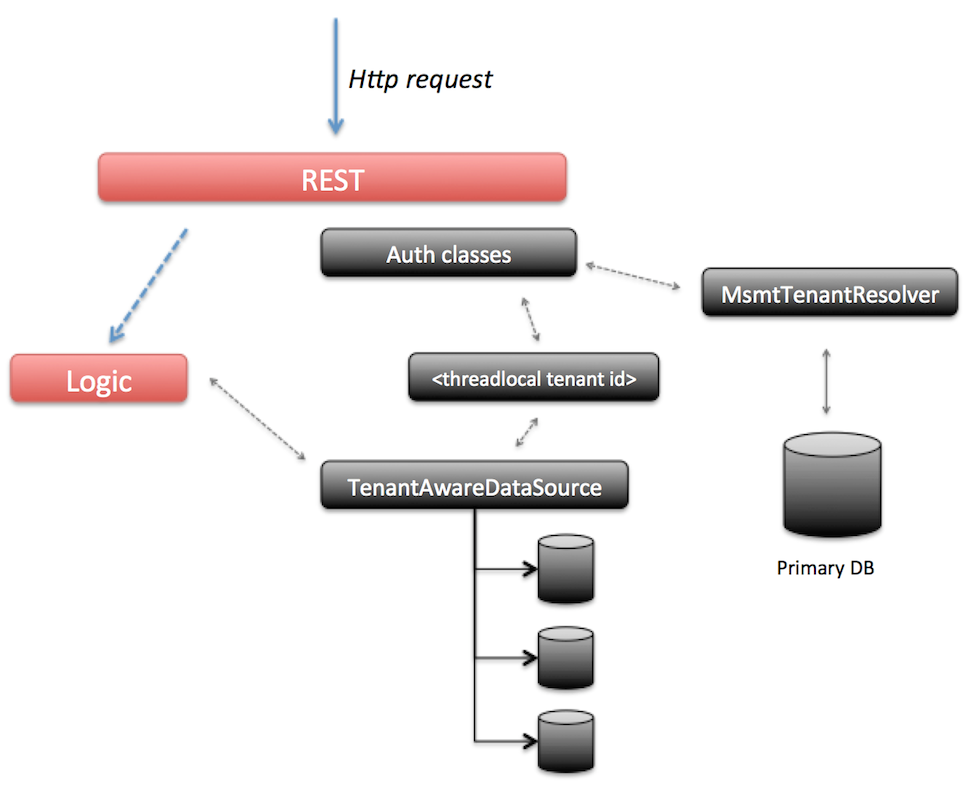
The MS-MT feature does have a technical impact on some other areas too:
- All default caches (process, forms, apps, script files, …) cache based on the db id as key. In MS-MT mode, the db id is not unique over tenants and the cache switches to a cache per tenant implementation.
- Event processing (for analytics) by default polls the database for new events which needs to be sent to Elastic Search. In MS-MT mode, the events for each tenant datasource are polled.
- The Process Engine job executor (responsible for timers and async continuations) polls the database for new jobs to execute. In MS-MT mode, this polling needs to happen for each tenant datasource.
- The Hibernate id generator keeps by default a pool of identifiers for each entity primary key in memory. Hibernate keeps the lastest id stored in a database table. In MS-MT mode however, there should be a pool for each tenant and the id generator needs to use the correct tenant datasource for refreshing the pool of ids.
- A similar story applies for the Process Engine id generator.
Getting started
To run Process Services, you need to have installed a multi-tenant license. Switching to MS-MT mode is done setting the tenancy.model property to isolated.
tenancy.model=isolated
When using MS-MT, there always needs to be a primary datasource. This datasource is configured exactly the same as when configuring the single datasource. For example when using a Mysql database:
datasource.url=jdbc:mysql://127.0.0.1:3306/primary-activiti?characterEncoding=UTF-8
com.mysql.cj.jdbc.Driver
datasource.username=alfresco
datasource.password=alfresco
hibernate.dialect=org.hibernate.dialect.MySQLDialect
Booting up Process Services now will create the regular tables in the primary-activiti schema, plus some additional tables specific to the primary datasource (such tables are prefixed with MSMT_). A default user with tenant manager capabilities is created (the login email and password can be controlled with the admin.email and admin.passwordHash properties) too.
One thing to remember is that there are no REST endpoints specific to MS-MT. All the existing tenant endpoints simply behave slightly different when running in MSMT mode. Using this tenant manager user (credentials in the basic auth header), it is now possible to add new tenants by calling the REST API:
POST http://your-domain:your-port/activiti-app/api/enterprise/admin/tenants
with the following JSON body:
{
"name" : "alfresco",
"configuration" : "tenant.admin.email=admin@alfresco.com\n
com.mysql.cj.jdbc.Driver\n
datasource.url=jdbc:mysql://127.0.0.1:3306/tenant-alfresco?characterEncoding=UTF-8\n
datasource.username=alfresco\n
datasource.password=alfresco"
}
Note that in some databases such as postgres, you may need to set the database.schema or database.catalog for database who work with catalogs.
Note the \n in the body of the configuration property.
Also note that this configuration will be stored encrypted (using the security.encryption.secret secret).
This will:
- Create a tenant named
alfresco. - Data of this tenant is stored in the database schema
tenant-alfresco. - A default tenant administrator user with the email login
admin@alfresco.comis created, with the default passwordadmin(this can be changed after log in).
When executing this request, in the logs you will see the tenant being created in MSMT mode:
INFO com.activiti.msmt.MsmtIdmService - Created tenant 'alfresco' in primary datasource (with id '1')
In the logs, you’ll see:
- The datasource connection pool for this tenant being created.
- The Liquibase logic creating the correct tables.
At the end, you’ll see the following message indicating all is ready:
INFO com.activiti.msmt.MsmtIdmService - Created tenant 'alfresco' in tenant datasource (with id '1')
INFO com.activiti.msmt.MsmtIdmService - Registered new user 'admin@alfresco.com' with tenant '1'
You can now log in into the web UI using admin@alfresco.com/admin, change the password and add some users. These users can of course also be added via the REST API using the tenant admin credentials.
A new tenant can easily be added in a similar way:
POST http://your-domain:your-port/activiti-app/api/enterprise/admin/tenants
with body
{
"name" : "acme",
"configuration" : "tenant.admin.email=admin@acme.com\n
com.mysql.cj.jdbc.Driver\n
datasource.url=jdbc:mysql://127.0.0.1:3306/tenant-acme?characterEncoding=UTF-8\n
datasource.username=alfresco\n
datasource.password=alfresco"
}
When the tenant admin for this tenant, admin@acme.com logs in, no data of the other one can be seen (as is usual in multi-tenancy). Also when checking the tenant-alfresco and tenant_acme schema, you’ll see the data is contained to the tenant schema.
The tenant manager can get a list of all tenants:
GET http://your-domain:your-port/activiti-app/api/enterprise/admin/tenants
[
{
"id": 2,
"name": "acme"
},
{
"id": 1,
"name": "alfresco"
}
]
To get specific information on a tenant, including the configuration:
GET http://your-domain:your-port/activiti-app/api/enterprise/admin/tenants/1
which gives:
{
"id": 1,
"name": "alfresco",
"created": "2016-04-27T09:22:33.511+0000",
"lastUpdate": null,
"domain": null,
"active": true,
"maxUsers": null,
"logoId": null,
"configuration": "tenant.admin.email=admin@alfresco.com\n
com.mysql.cj.jdbc.Driver\n
datasource.url=jdbc:mysql://127.0.0.1:3306/tenant-alfresco?characterEncoding=UTF-8\n
datasource.username=alfresco\n
datasource.password=alfresco"
}
Behavior
Assuming a multi-node setup: when creating new tenants, the REST call is executed on one particular node. After the tenant is successfully created, users can log in and use the application without any problem on any node (so the loadbalancer can simply randomly distribute for example). However, some functionality that depends on backgrounds threads (the job executor, for example) will only start after a certain period of time since the creation of the tenant on another node.
This period of time is configured via the msmt.tenant-validity.cronExpression cron expression (by default every 10 minutes).
Similarly, when a tenant is deleted, the deletion will happen on one node. It will take a certain amount of time (also configured through the msmt.tenant-validity.cronExpression property) before the deletion has rippled through all the nodes in a multi-node setup.
Note that tenant datasource configuration are not automatically picked up and require a reboot of all nodes. However, changing the datasource of a tenant should happen very infrequently.
Properties
There are some configuration properties specific to MS-MT:
tenancy.model: possible values areshared(default if omitted) orisolated. Isolated switched a multi-tenant setup to MS-MT.msmt.tenant-validity.cronExpression: the cron expression that determines how often the validity of tenants must be checked (see previous section) (by default every 10 minutes).msmt.async-executor.mode: There are two implementations of the Async job executor for the Activiti core engine. The default isisolated, where for each tenant a full async executor is booted up. For each tenant there will be acquire threads, a threadpool and queue for executing threads. The alternative value for this property isshared-queue*, where there are acquire threads for each tenant, but the actual job execution is done by a shared threadpool and queue. This saves some server resources, but could lead to slower job processing in case there are many jobs.msmt.bootstrapped.tenants: a semicolon separated list of tenant names. Can be used to make sure one node in a multi-node setup only takes care of the tenants in the list. Does require that the loadbalancer also uses similar logic.
Pluggability
Following interfaces can be used to replace the default implementations of MS-MT related functionality:
com.activiti.api.msmt.MsmtTenantResolver: used when the user authenticates and the tenant id is determined. The default implementation uses a database table (with caching) to store the user id to tenant id relationship.com.activiti.api.msmt.MsmtUserKeyResolver: works in conjuction with the DefaultMsmtTenantResolver, returns the user id for a user. By default returns the email or external id (if external id is used).com.activiti.api.datasource.DataSourceBuilderOverride: called when a tenant datasource configuration is used to create a datasource. If there is a bean on the classpath implementing this interface, the logic will be delegated to this bean to create thejavax.sql.DataSource. By default, a c3p0 DataSource / connection pool will be created for the configuration.