The external systems that can be integrated with Process Services are:
Email Server
The application sends out emails to users on various events. For example, when a task is assigned to the user.
Set the following properties to configure the email server:
| Property | Description |
|---|---|
| email.enabled | Enables or disables the email functionality as a whole. By default, it is set to false, therefore make sure to set it to true when you require the email functionality. |
| email.host | The host address of the email server. |
| email.port | The port on which the email server is running. |
| email.useCredentials | Boolean value. Indicates if the email server needs credentials to make a connection. If so, both username and password need to be set. |
| email.username | The username used as credentials when email.useCredentials is true. |
| email.password | The password used as credentials when email.useCredentials is true. |
| email.ssl | Defines if SSL is needed for the connection to the email server. |
| email.tls | Defines if TLS is needed for the connection to the email server. This needs to be true when Google mail is used as the mail server for example. |
| email.from.default | The email address that is used in the from field of any email sent. |
| email.from.default.name | The name that is used in the from field of the email sent. |
| email.feedback.default | Some emails will have a feedback email address that people can use to send feedback. This property defines this. |
Emails are created by a template engine. The emails can contain various links to the runtime system to bring the user straight to the correct page in the web application.
Set the following property to correct the links. The example in the following table uses localhost as host address
and /activiti-app as the context root:
| Property | Example |
|---|---|
| email.base.url | http://localhost:8080/activiti-app |
Elasticsearch
Elasticsearch is used in Process Services as a data store for generating analytics and reports. Elasticsearch is an open source data store for JSON documents. Its main features include fast full text search and analytics.
There are three configuration options for Elasticsearch:
Client
Using the client option, the application creates a client which connects to an Elasticsearch cluster. This approach is similar to connecting to a relational database.
Note: By default, an Elasticsearch client will always be created. In the client method, this is all that will be instantiated. In the embedded method, an Elasticsearch client will be created that connects to a cluster, which also includes the local node. In Elasticsearch terminology, they are referred to as client and data nodes.
No data is stored on the server on which the application is running. The data fully resides within the externally managed Elasticsearch cluster.
See the client and embedded properties for properties relevant to client and embedded set up types.
Embedded
Using the embedded client option, the Elasticsearch server is embedded within Process Services. Embedded instances can be configured to auto-discover other nodes.
Note: Booting up multiple Alfresco Process Services instances with Elasticsearch configured in embedded mode will not cluster. Use the property
elastic-search.discovery.typeinstead to configure clustering.
The properties specific to an embedded set up are:
| Property | Description |
|---|---|
| elastic-search.data.path | Defines where Elasticsearch will store its data on disk. $user_home$ can be used in the path. Make sure the application or application server has the right privileges to write to this path. To back up the Elasticsearch data easily, simply backup the content of this folder. |
See the client and embedded properties for properties relevant to client and embedded set up types.
Client and embedded properties
The following properties need to be configured in activiti-app.properties for Elasticsearch and are applicable to client and embedded set ups:
| Property | Description |
|---|---|
| elastic-search.server.type | The server type for Elasticsearch configuration. Set this to rest, embedded or client. To disable the client or embedded setups, use none. Note that when disabled event processing will not work either. |
| elastic-search.cluster.name | The name of the Elasticsearch cluster to connect to, for example activiti-elastic-search-cluster. |
| elastic-search.node.name | The name of the specific node of this server. The client node will have this name plus the suffix -client. In the embedded setup there will also be a data node with a -data suffix. |
| elastic-search.default.index.name | The name of the index in which the data will be stored. Only change this if there is a name clash for some reason in your Elasticsearch installation. |
| elastic-search.tenant.index.prefix | When running Alfresco Process Services with multi-tenancy, each tenant has its own index alias. Change this value to change the prefix applied to the alias. |
| elastic-search.enable.http | Enables the HTTP REST API of Elasticsearch. It is advised not to set this to true, unless traffic to it is strictly controlled by firewall rules. |
| elastic-search.enable.http.cors | Enables (when elastic-search.enable.http is true) cross-origin resource sharing, that is, whether a browser on another origin can do requests to Elasticsearch. |
Elasticsearch nodes (both client and data Elasticsearch nodes: therefore, this applies for both embedded and client setups) need to find each other to work in a clustered setup. This can be configured using the property elastic-search.discovery.type and setting it as either multicast or unicast.
When set to multicast, the following properties can be set:
| Property | Description |
|---|---|
| elastic-search.discovery.multicast.group | The multicast group address to use, for example 224.2.2.4. |
| elastic-search.discovery.multicast.port | The multicast port to use, for example 54328. |
| elastic-search.discovery.multicast.ttl | The time-to-live of the multicast message, for example 3. |
| elastic-search.discovery.multicast.address | The address to bind to. For example for all available network interfaces 0.0.0.0. |
When set to unicast, only one property needs to be set:
| Property | Description |
|---|---|
| elastic-search.discovery.hosts | The way nodes find each other. This is in the format <host>:<port> and can be set as an array or a comma separated list. |
REST
Process Services can use a REST connection to communicate with a remote instance of Elasticsearch. The application creates a Java Low Level REST client, which allows you to configure Process Services to index event data into a remote Elasticsearch service. The REST client internally uses the Apache HTTP Async Client to send HTTP requests. This allows communication with an Elasticsearch cluster through HTTP.
A REST connection between Elasticsearch and Process Services has three points to be aware of:
- REST operations made using the native transport protocol are not supported. The Elasticsearch service exposes only the REST API and not the transport protocol. Operations must therefore be run across an HTTP connection.
- No data is stored on the server on which the application is running. The data fully resides within the Elasticsearch cluster in the remote environment.
- In multi-tenant setups, four indexes are created per tenant.
For more details regarding the REST client, see Java Low Level REST Client.
For information about the compatibility between the REST client and the remote Elasticsearch cluster environment, see Communicating with an Elasticsearch Cluster using HTTP.
The properties specific to a REST set up are:
| Property | Description |
|---|---|
| elastic-search.server.type | The server type for Elasticsearch configuration. Set this to rest, embedded or client. |
| elastic-search.rest-client.port | The port running Elasticsearch, for example 9200. |
| elastic-search.rest-client.connect-timeout | Connection timeout for the REST client, for example 1000. |
| elastic-search.rest-client.socket-timeout | Socket timeout for the REST client, for example 5000. |
| elastic-search.rest-client.address | IP address of the REST client, for example localhost. |
Back up Elasticsearch data
Backing up the data stored in Elasticsearch is described in detail in the Elastic search documentation. When using the snapshot functionality of ElasticSearch, you must enable the HTTP interface and create firewall rules to prevent the general public from accessing it.
Event processing for analytics
The main concept of event processing is depicted in the following diagram.
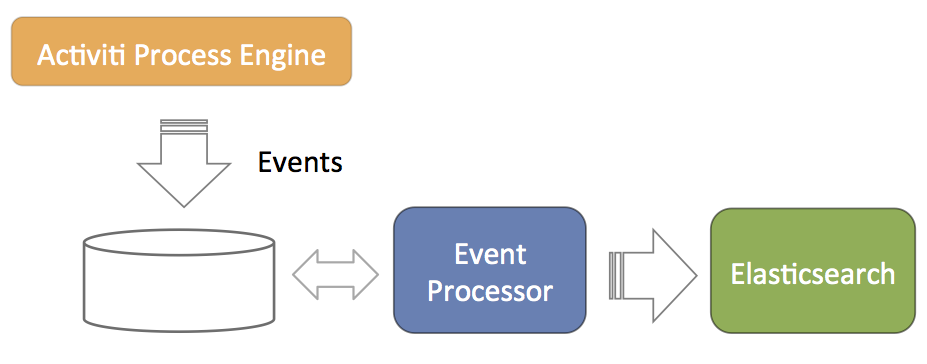
- The Process Engine is configured to generate events related to process execution (for example, processes started, task completed, and so on). These events are stored in the database such that there is no problem with database transactions. Meaning, writing the events to the database succeeds or fails with the regular process execution data.
- A component called event processor will asynchronously check for new entries in the database table for the events. The events will be processed and transformed to JSON.
- The JSON event is asynchronously sent to Elasticsearch. From that point on the data will show up in the reports.
The event processor is architected to work without collisions in a multi-node clustered setup. Each of the event processors will first try to lock events before processing them. If a node goes down during event processing (after locking), an expired events processor component will pick them up and process them as regular events.
The event processing can be configured, however leaving the default values as they are helps cater for typical scenarios.
| Property | Description |
|---|---|
| event.generation.enabled | Set to false if no events need to be generated. Do note that the reporting/analytics event data is then lost forever. The default value is true. |
| event.processing.enabled | Set to false to not do event processing. This can be useful in a clustered setup where only some nodes do the processing. The default value is true. |
| event.processing.blocksize | The number of events that are attempted to be locked and fetched to be processed in one transaction. Larger values equate to more memory usage, but less database traffic. The default value is 100. |
| event.processing.cronExpression | The cron expression that defines how often the events generated by the Process Engine are processed (that is, read from the database and fed into Elastic Search). By default 30 seconds. If events do not need to appear quickly in the analytics, it is advised to make this less frequent to put less load on the database. The default value is 0/30 \* \* \* \* ?. |
| event.processing.expired.cronExpression | The cron expression that defines how often expired events are processed. These are events that were locked, but never processed (such as when the node processing them went down). The default value is 0 0/30 \* \* \* ?. |
| event.processing.max.locktime | The maximum time an event can be locked before it is seen as expired. After that it can be taken by another processor. Expressed in milliseconds. The default value is 600000. |
| event.processing.processed.events.action | To keep the database table where the Process Engine writes the events small and efficient, processed events are either moved to another table or deleted. Possible values are move and delete. Move is the safe option, as it allows for reconstructing the Elasticsearch index if the index was to get corrupted for some reason. The default value is move. |
| event.processing.processed.action.cronExpression | The cron expression that defines how often the action above happens. The default value is 0 25/45 \* \* \* ?. |
Rebuild indexes
Occasionally, an Elasticsearch index can get corrupted and become unusable. All data that are sent to Elasticsearch is stored in the relational database (except if the property event.processing.processed.events.action has been set to delete, in which case the data is lost).
You might have to rebuild the indexes when changing the core Elasticsearch settings (for example, number of shards).
Events are stored in the ACT_EVT_LOG table before they are processed. The IS_PROCESSED_ flag is set to 0 when inserting an event and changing it to 1 to process for ElasticSearch. An asynchronous component will move those table rows with 1 for the flag to the PROCESSED_ACTIVITI_EVENTS.
Therefore, to rebuild the Elasticsearch index, you must do the following:
- Remove the data from Elasticsearch (deleting the data folders for example in the embedded mode)
- Copy the rows from
PROCESSED_ACTIVITI_EVENTStoACT_EVT_LOGand setting theIS_PROCESSEDflag to0again.
Note also, due to historical reasons, the DATA_ column has different types in ACT_EVT_LOG (byte array) and PROCESSED_ACTIVITI_EVENTS (long text). So a data type conversion is needed when moving rows between those tables.
See the example-apps folder that comes with Process Services. It has an event-backup-example folder, in which a Maven project can be found that carries out the data type conversion. You can also use this to back up and restore events. Note that this example uses Java, but it can also be done with other languages. It first writes the content of PROCESSED_ACTIVITI_EVENTS to a .csv file. This is also useful when this table becomes too big in size: store the data in a file and remove the rows from the database table.
Microsoft Office
The Microsoft Office integration (opening an Office document directly from the browser) doesn’t need any specific configuration. However, the protocol used for the integration mandates the use of HTTPS servers by default. This means that Process Services must run on a server that has HTTPS and its certificates are correctly configured.
If this is not possible for some reason, change the setting on the machines for each user to make this feature work.
For Windows, see:
http://support.microsoft.com/kb/2123563
For OS X, execute following terminal command:
defaults -currentHost write com.microsoft.registrationDB hkey_current_user\\hkey_local_machine\\software\\microsoft\\office\\14.0\\common\\internet\\basicauthlevel -int 2
Note that this is not a recommended approach from a security point of view.