Back up
There are a number of ways to back up Search Services. You can set the Solr indexes backup properties either by:
- Editing the ‘solrcore.properties’ file
- Using a JMX client, such as JConsole. Note: This feature is only available when you are using Alfresco Content Services Enterprise.
This task shows you how to specify the Solr backup directory by using the <SOLR_HOME>/solrhome/templates/rerank/conf/solrcore.properties
To set the Solr backup directory using the solrcore.properties file, set the value of the following properties to the full path where the backups should be kept after starting solr (remember to make sure it is an exsisting location and the path is the correct format depending on if uisng MAC/Windows/Linux):
solr.backup.dir=
Then stop solr and repeat the same step for each of the cores created after startup. The above path should have copied the path to the cores at creation but alfresco and archive would need to be specified for each core.
To set the Solr backup directory for each core use the <SOLR_HOME>/solrhome/alfresco/conf/solrcore.properties and <SOLR_HOME>/solrhome/archive/conf/solrcore.properties file and edit the same property as above.
Then restart solr with these properties added and then use the admin console to edit the frequency of the backup.
You can only see the Admin Console if you’re an administrator.
To edit the frequency of the backup, you can use the Cron Expression via the admin console.
- Launch the Admin Console. For information, see Launch Admin Console.
-
In the Repository Services section, click Search Service.
You see the Search Service page.
-
Scroll down to the Backup Settings section.
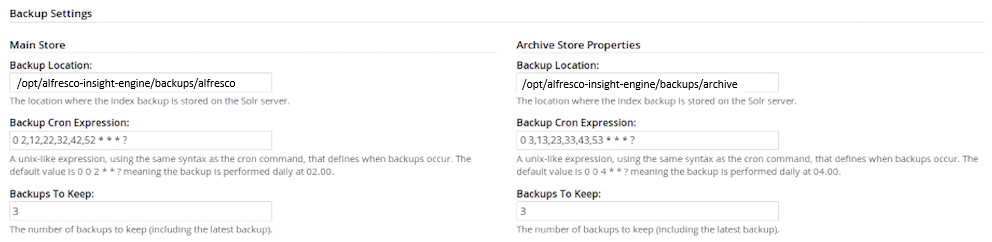
Here, you can edit backup properties for each core of the Solr index: Main Store and Archive Store.
- Backup Cron Expression: Specifies a Quartz cron expression that defines when backups occur. Solr creates a timestamped sub-directory for each index back up you make.
- Backups To Keep: Specifies the maximum number of index backups that Solr should store.
- Click Save.
This task shows how to specify the Solr backup directory by using the <TOMCAT_HOME>/shared/classes/alfresco-global.properties file.
To set the Solr backup directory using the alfresco-global.properties file, set the value of the following properties to the full path where the backups should be kept:
solr.backup.archive.remoteBackupLocation=
solr.backup.alfresco.remoteBackupLocation=
The values set on a subsystem will mean that the property values from configuration files may be ignored. Use the solrcore.properties or JMX client to set the backup location.
If you have installed the Oracle Java SE Development Kit (JDK), you can use the JMX client, JConsole, to backup Solr indexes, edit Solr backup properties and setup the backup directory.
- You can set the backup of Solr indexes using the JMX client, such as JConsole on the JMX MBeans > Alfresco > Schedule > DEFAULT > MonitoredCronTrigger > search.alfrescoCoreBackupTrigger > Operations > executeNow tab. The default view is the Solr core summary. Alternatively, navigate to MBeans > Alfresco > SolrIndexes > coreName > Operations > backUpIndex tab. Type the directory name in the remoteLocation text box and click backUpIndex.
-
Solr backup properties can be edited using the JMX client on the JMX MBeans > Alfresco > Configuration > Search > managed > solr6 > Attributes tab. The default view is the Solr core summary.

- To use JMX client to setup Solr backup directory, navigate to MBeans tab > Alfresco > Configuration > Search > managed > solr > Attributes and change the values for
solr.backup.alfresco.remoteBackupLocationandsolr.backup.archive.remoteBackupLocationproperties. -
You may also trigger a backup with an HTTP command which instructs the
/replicationhandler to backup Solr, for example:http://localhost:8983/solr/alfresco/replication?command=backup&location=&numberToKeep=4&wt=xmlwhere:
locationspecifies the path where the backup will be created. If the path is not absolute then the backup path will be relative to Solr’s instance directory.numberToKeepspecifies the number of backups to keep.
Solr logging
You can set different debug logging levels for Solr components using the Solr log4j properties.
-
Locate the
<solrRootDir>/log4j-solr.propertiesfile. -
Edit it to add your required logging setting. For example:
log4j.logger.org.alfresco.solr.tracker.MetadataTracker=DEBUG -
Changes to the log4j-solr.properties file will be re-read by Solr when it starts up. If you need to make changes to the logging level while the system is running, going to the following URL (either in a browser or for example, using curl) will cause Solr to re-load the properties file.
https://<solrHostName>:<solrPort>/solr/admin/cores?action=LOG4J&resource=log4j-solr.properties
Document fingerprints
Alfresco Content Services 6.2 and above provides support for Document Fingerprints to find related documents. Document Fingerprinting is performed by algorithms that map data, such as documents and files to shorter text strings, also known as fingerprints. This feature is exposed as a part of the Alfresco Full Text Search Query Language.
NOTE: Document fingerprints is disabled by default, for more see Document Fingerprints
Document Fingerprints can be used to find similar content in general or biased towards containment. The language adds a new FINGERPRINT keyword:
FINGERPRINT:<DBID | NODEREF | UUID>
By default, this will find documents that have any overlap with the source document. The UUID option is likely to be the most useful as UUID is present in the public API. To specify a minimum amount of overlap, use:
FINGERPRINT:<DBID | NODEREF | UUID>_<%overlap>
FINGERPRINT:<DBID | NODEREF | UUID>_<%overlap>_<%probability>
To find documents that have 20% overlap with the document 1234, use:
FINGERPRINT:1234_20
To execute a faster query that will be 80% confident anything brought back will overlap by 20%, use:
FINGERPRINT:1234_20_80
To support fingerprint queries, additional information is added to the Solr 6 index using the rerank template. This makes the indexes approximately 15% bigger. Document Fingerprint can only be disabled by changing the schema.
Similarity and containment
Document similarity covers duplicate detection, near duplicate detection, and finding different renditions of the same content. This is important to find and reduce redundant information. Fingerprints can provide a distance measure to other documents, often based on Jaccard distance/ similarity coefficient, to support more like this. The distance can also be used as a basis for graph traversal.
The Jaccard similarity coefficient is a commonly used indicator of the similarity between two sets. For sets A and B it is defined to be the ratio of the amount of common content to the total content of two documents, as defined here:
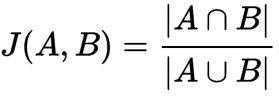
This distance can be used to compare the similarity of any two documents with any other pair of documents.
Containment is a related concept but is more about inclusion. For example, many email threads include parts or all of previous messages. Containment is not symmetrical like the measure of similarity above, and is defined as:
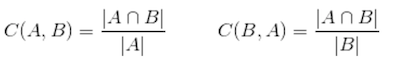
It represents how much of the content of a given document is common to another document. This distance can be used to compare a single document (A) to any other document.
Minhashing
Minhashing is a technique for quickly estimating how similar two sets of documents are. It is an example of a text processing pipeline.
First, the text is split into a stream of words. These words are then combined into five word sequences, known as shingles, to produce a stream of shingles. The 5-word shingles are then hashed, for example, in 512 different ways; keeping the lowest hash value for each hash. This results in 512 repeatably random samples of 5-word sequences from the text represented by the hash of the shingle. The same text will generate the same set of 512 minhashes. Similar text will generate many of the same hashes. It turns out that if 10% of all the min hashes from two documents overlap then it is a great estimator that J(A,B) = 0.1.
- Why 5 word sequences?: Word embedding suggests 5 or more words are enough to describe the context and meaning of a central word. Based on the distribution of words for 2 word shingles, 3 word shingles, 4 word shingles, and 5 word shingles found on the web, it was found that at 5 word shingles, the frequency distribution flattens and broadens compared with the trend seen for 1, 2, 3 and 4 word shingles.
- Why 512 hashes?: With a well distributed hash function this should give good hash coverage for 2,500 words and around 10% for 25,000, or something like 100 pages of text. We used a 128-bit hash to encode both the hash set position (see later) and hash value to minimise collision compared with a 64 bit encoding including bucket/set position.
Example 1
A document contains a single sentence of The quick brown fox jumps over the lazy dog, that would be broken down into the following 5-word long shingles:
- The quick brown fox jumps
- quick brown fox jumps over
- brown fox jumps over the
- fox jumps over the lazy
- jumps over the lazy dog
So, our document as a set looks like:
Set A = new Set(["The quick brown fox jumps", "quick brown fox jumps over", "brown fox jumps over the", "fox jumps over the lazy", "jumps over the lazy dog"]);
These sets of shingles can then be compared for similarity using the Jaccard Coefficient.

Example 2
Here are two summaries of the 1.0 and 1.1 CMIS specification. It demonstrates, amongst other things, how sensitive the measure is to small changes. Adding a single word affects 5 shingles.

The content overlap of the full 1.0 CMIS specification found in the 1.1 CMIS specification, C(1.0, 1.1) is approximately 52%.