There are a number of processes and procedures for maintaining and administering the Search Enterprise environment.
Pre-indexing considerations
The Exact Term search feature that allows searching using the equals operator =, is disabled by default to save index space.
It’s possible to enable it for specific properties and property types using the /alfresco/search/elasticsearch/config/exactTermSearch.properties configuration file located in the Alfresco Repository.
| Property | Description |
|---|---|
| alfresco.cross.locale.datatype.0 | A new cross locale field is added for any property of this data-type to enable exact term search. For example, {http://www.alfresco.org/model/dictionary/1.0}text. The Exact Term search is disabled by default. |
| alfresco.cross.locale.property.0 | A new cross locale field is added for the property to enable exact term search. For example, {http://www.alfresco.org/model/content/1.0}content. The Exact Term search is disabled by default. |
You can add as many data types and properties as you like by adding lines and incrementing the associated index:
alfresco.cross.locale.datatype.0={http://www.alfresco.org/model/dictionary/1.0}text
alfresco.cross.locale.datatype.1={http://www.alfresco.org/model/dictionary/1.0}content
alfresco.cross.locale.datatype.2={http://www.alfresco.org/model/dictionary/1.0}mltext
alfresco.cross.locale.property.0={http://www.alfresco.org/model/content/1.0}content
To overwrite this configuration when using Docker compose you can mount this file as an external volume. The following sample describes a local configuration to be applied to the Elasticsearch Search Subsystem when using Docker compose:
services:
alfresco:
volumes:
- ./exactTermSearch.properties:/usr/local/tomcat/webapps/alfresco/WEB-INF/classes/alfresco/search/elasticsearch/config/exactTermSearch.properties
Note: Once complete you must perform a re-index. It is recommended you enable the exact term feature before you start creating an index.
You can also add these environment variables directly to the Alfresco JAVA_OPTS section of your Docker compose file.
services:
alfresco:
image: quay.io/alfresco/alfresco-content-repository:23.1.0
mem_limit: 1900m
environment:
JAVA_TOOL_OPTIONS: -Dencryption.keystore.type=JCEKS -Dencryption.cipherAlgorithm=DESede/CBC/PKCS5Padding -Dencryption.keyAlgorithm=DESede -Dencryption.keystore.location=/usr/local/tomcat/shared/classes/alfresco/extension/keystore/keystore -Dmetadata-keystore.password=mp6yc0UD9e -Dmetadata-keystore.aliases=metadata -Dmetadata-keystore.metadata.password=oKIWzVdEdA -Dmetadata-keystore.metadata.algorithm=DESede
JAVA_OPTS: -Ddb.driver=org.postgresql.Driver
...
-alfresco.cross.locale.datatype.0={http://www.alfresco.org/model/dictionary/1.0}text
-alfresco.cross.locale.datatype.1={http://www.alfresco.org/model/dictionary/1.0}content
-alfresco.cross.locale.datatype.2={http://www.alfresco.org/model/dictionary/1.0}mltext
-alfresco.cross.locale.property.0={http://www.alfresco.org/model/content/1.0}content
...
Mapping
When you index a document that contains a new field, Search Enterprise adds the field dynamically to the document, or to the inner objects within a document. Inner objects inherit the dynamic setting from their parent object or from the mapping type. A dynamic parameter controls whether new fields are added dynamically. The default value is true and should be disabled to avoid a large index, unless a large index is necessary. This can be done when you create the index, using the following command:
curl -XPUT '<Search Enterprise URL>:<port>/<index name>?pretty' -H 'Content-Type: application/json' -d'
{
"mappings": {
"dynamic": "false"
}
}'
Sharding
A shard is a small chunk of memory where indexed data is stored. Before you index Search Enterprise you can configure how many shards and replicas you want to use. How you configure the shards will depend on your intended data volume and the size of each shard. Here’s the command to use:
curl -XPUT '<Search Enterprise URL>:<port>/<index name>?pretty' -H 'Content-Type: application/json' -d'
{
"settings" :{
"number_of_shards":<expected number of shards>,
"number_of_replicas":<0 for no replica, 1 for 1 replica of each shards and so on>
}
}
Near real-time search
Per-segment searching has decreased the delay between indexing a document and when it is able to be visible to your search queries. In Search Enterprise, the lightweight process of writing and opening a new segment is called a refresh. By default, each shard is automatically refreshed every second. Using parameters you can increase the refresh rate to increase the speed of the indexing process, or you can disable it completely.
To speed up the process:
curl -XPUT "<Search Enterprise URL>:<port>/<index name>/_settings" -H 'Content-Type: application/json' -d '{ "index" : { "refresh_interval" : "60s" }}'
To disable the refresh rate:
curl -XPUT "<Search Enterprise URL>:<port>/<index name>/_settings" -H 'Content-Type: application/json' -d '{ "index" : { "refresh_interval" : "-1" }}'
Alfresco Elasticsearch connector
Indexing is provided by a Spring boot application called the Elasticsearch connector. This application contains two main components that build and maintain the index in Elasticsearch.
-
Live Indexing: Metadata, and Content and Permissions from Alfresco Repository are consumed using ActiveMQ messages so they can be indexed in the Elasticsearch server. The information created and updated in the Alfresco Repository is not immediately available in Elasticsearch, because it takes time to process the messages coming from the Alfresco Repository. The previous Eventual consistency approach, based on transactions and used for Solr deployments, has been replaced by this new approach based on ActiveMQ messages.
-
Re-indexing: Indexing the information of a pre-populated Alfresco Repository or catching up with Alfresco Repositories that have missed some ActiveMQ messages is provided by the re-indexing component. Metadata and Permissions from the Alfresco Repository is retrieved using a direct JDBC connection to the Alfresco Database. The re-indexing application also generates content indexing messages in ActiveMQ in order to get the content indexed. It may take some time to process all these requests after the re-indexing application has finished.
New Repository
When creating a new Alfresco Repository you must use the Elasticsearch connector applications in the following sequence:
- Start the Content Services Stack, including the Elasticsearch connector live indexing services, and the Elasticsearch server.
- Configure the Elasticsearch connector re-indexing app to point to the database, the Elasticsearch server, and the ActiveMQ server.
- Run the re-indexing app from the command line replacing the connection details as appropriate:
$ java -jar alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.jobName=reindexByIds \
--spring.elasticsearch.rest.uris=http://localhost:9200 \
--spring.datasource.url=jdbc:postgresql://localhost:5432/alfresco \
--spring.datasource.username=alfresco \
--spring.datasource.password=alfresco \
--spring.activemq.broker-url=tcp://localhost:61616?jms.useAsyncSend=true \
--alfresco.reindex.prefixes-file=file:reindex.prefixes-file.json
When completed successfully you will see:
o.s.batch.core.step.AbstractStep : Step: [reindexByIdsStep] executed in 4s952ms
o.a.r.w.ElasticsearchRepoEventItemWriter : Total indexed documents:: 845
o.a.r.listeners.JobLifecycleListener : Current Status: COMPLETED
Once the command has completed, metadata and permissions from the out-of-the-box repository nodes are indexed in the Elasticsearch server. Additionally, the Elasticsearch connector live indexer will add existing content, the new metadata, permissions, and new content when nodes are created, updated or deleted.
Existing Repository
When using a pre-populated Alfresco Repository, use the Elasticsearch connector applications in the following sequence:
- Ensure the Content Services Stack with SOLR, which is configured as the search subsystem, is running.
- Start the Elasticsearch server.
- Configure the Elasticsearch connector re-indexing app to point to the database, the Elasticsearch server, and the ActiveMQ server.
- Run the re-indexing app and replace the connection details as appropriate:
$ java -jar alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.jobName=reindexByIds \
--spring.elasticsearch.rest.uris=http://localhost:9200 \
--spring.datasource.url=jdbc:postgresql://localhost:5432/alfresco \
--spring.datasource.username=alfresco \
--spring.datasource.password=alfresco \
--spring.activemq.broker-url=tcp://localhost:61616?jms.useAsyncSend=true \
--alfresco.reindex.prefixes-file=file:reindex.prefixes-file.json
When completed successfully you will see:
o.a.r.w.ElasticsearchRepoEventItemWriter : Total indexed documents:: 80845
o.a.r.listeners.JobLifecycleListener : Current Status: COMPLETED
Once the command has completed, metadata from any existing Repository nodes will be indexed in the Elasticsearch server. Additionally, the Elasticsearch connector live indexer will add existing content, which may take a while. Ensure ActiveMQ is available until all the content transformation request messages have been processed. Then change the Alfresco Repository configuration to use the Elasticsearch as the search subsystem and then re-start the Repository.
Note: To ensure all the content transformation requests have been processed the ActiveMQ Web Console should be used. By default, the Web Console is available at
http://127.0.0.1:8161and accessed using default credentials. Any queues related to content transformation, usually throughacs-repo-transform-request, should not have any pending messages.
Partial Indexing
Over time some data may not be indexed correctly. This can be caused by prolonged network connectivity issues. The re-indexing application provides two strategies to fill the gaps in the Elasticsearch index:
- Fetch by IDS (
alfresco.reindex.jobName=reindexByIds): index nodes in an interval of databaseALF_NODE.idcolumn. - Fetch by DATE (
alfresco.reindex.jobName=reindexByDate): index nodes in an interval of databaseALF_TRANSACTION.commit_time_mscolumn.
Ids Range
The following sample re-indexes all the nodes in the Alfresco Repository which have an ALF_NODE.id value between 1 and 10000.
java -jar target/alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.jobName=reindexByIds \
--alfresco.reindex.pagesize=100 \
--alfresco.reindex.batchSize=100 \
--alfresco.reindex.fromId=1 \
--alfresco.reindex.toId=10000 \
--alfresco.reindex.concurrentProcessors=2
Date Range
The following sample re-indexes all the nodes in the Alfresco Repository which have a value for ALF_TRANSACTION.commit_time_ms between 202001010000 and 202104180000. Date time values are written in the format yyyyMMddHHmm.
java -jar target/alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.jobName=reindexByDate \
--alfresco.reindex.pagesize=100 \
--alfresco.reindex.batchSize=100 \
--alfresco.reindex.concurrentProcessors=6 \
--alfresco.reindex.fromTime=202001010000 \
--alfresco.reindex.toTime=202104180000
Note: Bulk indexing by date range is not recommended for the entire repository because the meta-data indexing speed is slower. Indexing by date range is intended to be used for a targeted re-index of a small portion of the repository. For example, all updates in the last 24 hours.
Deploying at Scale
This section describes how to run Search Enterprise at scale. Recommendations are based on testing carried out against a 50 million node repository.
The following services are required:
- Alfresco Content Repository deployed as a Tomcat server using the
alfresco.warapplication. - Alfresco Database to store metadata and other relevant information for the content repository.
- Alfresco Transform Service deployed as a Spring boot application with several transformation services (ImageMagick, LibreOffice, PDF Renderer and LibreOffice).
- Alfresco Shared File store deployed as a Spring boot application to serve transformed files by the Transform Service.
- Alfresco Elasticsearch Connector deployed as a Spring boot application with several indexing services, mediation, metadata, and content.
- Alfresco ActiveMQ which is message-oriented middleware and shares messages between the content repository, the Elasticsearch connector and the Transform Service.
- Elasticsearch server.
Identifying critical paths
To identify the services used for the different features provided by Search Enterprise the following critical paths should be reviewed:
- Indexing metadata and permissions
- Indexing content
- Searching metadata and content
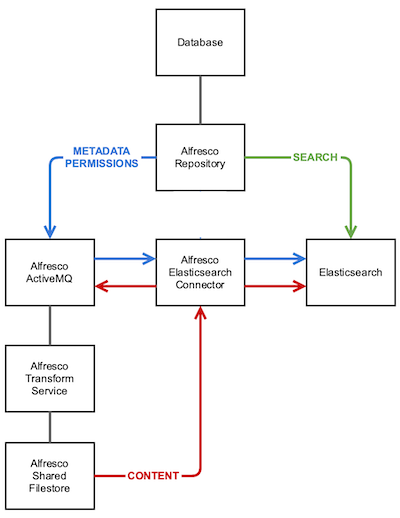
Metadata and Permissions
Each time a node is created or updated in the content repository, new messages with metadata and permissions are sent to ActiveMQ. The Elasticsearch connector consumes these messages and sends the indexing requests to the Elasticsearch server.
Content
Every time a content node is created or updated in the content repository, new messages are sent to ActiveMQ. The Elasticsearch connector consumes these messages from ActiveMQ and creates new transformation messages back into ActiveMQ. The Content Repository consumes the transformation messages and offloads the transformation of documents into plain text to the Transform Service. Once the transformation has been performed, the content repository produces a transformation complete message in ActiveMQ and uploads the plain text file to a Shared File store. The Elasticsearch connector consumes these messages and downloads the extracted text from the Shared File store. Then the text in the document is sent for indexing to the Elasticsearch server.
Searching metadata and content
Searching operations are handled by the content repository REST API. Depending on the search syntax used (only AFTS is currently supported), the content repository translates the search query to the Elasticsearch REST API language and sends the search request to Elasticsearch.
Metadata indexing performance
A misconfigured or deployed system can result in a significant delay between the time when documents are created or updated in the content repository and when they appear in the search results (indexed in the Elasticsearch server).
The following information describes how to identify bottlenecks in the system’s performance. It also gives recommendations on how to mitigate those bottlenecks when only indexing metadata.
Alfresco Repository
When the content repository is updating the database the document’s metadata in the database sends messages to the ActiveMQ topic alfresco.repo.event2. The rate of created or updated documents depends on the content repository cluster performance.
Recommendations:
- Increase resources for the server if CPU load or memory consumption is high.
- Increase database pool if no connections are available.
- Increase the number of threads if no threads are available.
- Increase the number of content repository nodes in the cluster.
Database
The database is updated to create new nodes or to modify existing ones. Additionally, the queries are executed in the database to populate metadata for returned entities in the REST API responses for search queries. These operations are mainly related to ALF_NODE and ALF_NODE_PROPERTIES tables.
Recommendations:
- Increase resources for the server if CPU load or memory consumption is high.
- Regularly update statistics for
ALF_NODEandALF_NODE_PROPERTIEStables to optimise query planner performance.
Elasticsearch connector
This service consumes messages from the ActiveMQ topic alfresco.repo.event2 and produces or consumes ActiveMQ messages from the queue org.alfresco.search.metadata.event.
Recommendations:
- Always use a pool of connections to ActiveMQ (
spring.activemq.pool.enabledset totruewithspring.activemq.pool.max-connectionssized). - Increase the number of consumers for the
live-indexing-mediationcomponent if the messages enqueued count is significantly greater than messages dequeued for the ActiveMQ topicalfresco.repo.event2. - Increase the number of consumers for the
live-indexing-metadatacomponent if the messages enqueued count is significantly greater than messages dequeued for the ActiveMQ queueorg.alfresco.search.metadata.event.
ActiveMQ
ActiveMQ transports messages from the content repository and the Elasticsearch connector. It also communicates between the content repository and the Transform Service communication.
Recommendations:
- Increase resources for the server if CPU load or memory consumption is high.
Elasticsearch server
The Elasticsearch server gets indexing requests from the Elasticsearch connector. If all other services are working as expected, an increment in messages enqueued without the dequeuing operation for queue org.alfresco.search.metadata.event may indicate the Elasticsearch server requires more resources. Slow responses for a search query can also indicate insufficient resources for the server.
Recommendations:
- Increase resources for the server if CPU load or memory consumption is high.
- Increase resources for the server if ingestion rate is decreasing with higher volumes of data.
Permissions indexing performance
Alfresco Repository
Recommendations:
- Increase resources for the server if CPU load or memory consumption is high.
- Increase database pool if no connections are available.
- Increase the number of threads if no threads are available.
- Increase the number of content repository nodes in the cluster.
Content indexing performance
Alfresco Repository
Recommendations:
- Increasing the number of concurrent consumers for the ActiveMQ queue
acs-repo-transform-request, can lead to missed content transformations. If you keep this value below10all the documents will be transformed.
Elasticsearch connector
Recommendations:
- Increase the timeout used to contact the Shared file store via HTTP, you set the value in
alfresco.sharedFileStore.timeout. This helps to avoid issues when the Shared File store response is slower than usual under a large load. - Increase the content retry delay used to retrieve content from the Shared File store, you set the value in
alfresco.content.event.retry.delay. This helps when you are uploading a large document into the system. - Select the correct configuration for the Shared File store content age scheduler. If you have disk space issues you can reduce it. You must consider you may find unexpected exceptions with a content reinsert request.
Searching performance
The Elasticsearch connector uses an out-of-the-box Elasticsearch server, for more see Tune for search speed.
Re-indexing
The Re-indexing app has been tested on reading replicas with a Postgres database. Tests have been performed on the local environment and AWS. To run database read replicas in AWS follow these guidelines AWS read replicas.
For using the read replica in the re-indexing phase, configure the reindexing component for targeting the correct read replica:
spring.datasource.url=jdbc:postgresql://<READ_REPLICA_ADDRESS>:<READ_REPLICA_PORT>/alfresco
Re-index using remote partitioning
It can take a large amount of time when re-indexing a large Alfresco Repository instance using a single re-index process. You can scale the re-index node vertically to improve performance, but this may also not enough. Using remote partitioning, and a Spring Batch feature, you can scale horizontally the Re-indexing service.
┌─────────────────────────┐ ┌────────────────┐
│ Manager │ │ Worker 1 │
│ │ Produce ┌────────────►│ ├───┐
│ │ partition │ │* Read partition│ │
│ * DB Schema Validation │ requests┌───┴──────┐ │* Index nodes │ │
│ ├──────────►│ ActiveMQ │ └──────┬─────────┘ │
│ * Partition creation │◀──────────┤ │ ◀───────────┘ │
│ │ └───┬──────┘ │
│ │ Consumes │ ▲ │
│ │ workers │ │ │
│ │ replies │ │ │
│ │ │ │ │
│ │ │ │ │
│ │ │ │ │
│ │ │ │ ┌────────────────┐ │
└───────────┬─────────────┘ │ └───────────┤ Worker n │ │
│ │ │ │ │
│ └────────────►│* Read partition│ │
│ │* Index nodes │ │
│ └────────┬───────┘ │
│ ┌────────────┐ │ │
│ │ Shared │◄──────────────────────────┘ │
└──────────►│ Database │ │
│ │◄──────────────────────────────────────┘
└────────────┘
This solution requires a manager node that executes verification steps, like database schema validation, and creates partitions and multiple worker nodes that index the partition. The manager sends partitions to the worker using ActiveMQ.
To use this feature you need to run a manager node and at least a worker node. To scale up the system you can increase the number of worker nodes by setting the property alfresco.reindex.partitioning.grid-size. The number of worker nodes usually equals the grid size, but if it is more a worker will consume multiple partitions.
The system will automatically select the partition strategy depending on the job name, currently there is:
- Partition by id range
- Partition by date range
Both strategies split the specified range into multiple ranges depending on the grid size.
Manager:
java -jar alfresco-elasticsearch-reindexing-4.0.1-app.jar \
--alfresco.reindex.jobName=reindexByIds \
--alfresco.reindex.partitioning.type=manager \
--alfresco.reindex.pagesize=100 \
--alfresco.reindex.batchSize=100 \
--alfresco.reindex.fromId=0 \
--alfresco.reindex.toId=10000 \
--spring.batch.datasource.url=jdbc:postgresql://<IP address of host>:<port number>/alfresco \
--spring.batch.datasource.username=alfresco \
--spring.batch.datasource.password=alfresco \
--spring.batch.datasource.driver-class-name=org.postgresql.Driver \
--spring.batch.drop.script=classpath:/org/springframework/batch/core/schema-drop-postgresql.sql \
--spring.batch.schema.script=classpath:/org/springframework/batch/core/schema-postgresql.sql
--spring.elasticsearch.rest.uris=http://<IP address of host>:<port number>
--spring.datasource.url=jdbc:postgresql://<IP address of host>:<port number>/alfresco
--spring.datasource.username=alfresco
--spring.datasource.password=alfresco
--spring.activemq.broker-url=tcp://localhost:<port number>
Worker:
java -jar alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.partitioning.type=worker \
--alfresco.reindex.pagesize=100 \
--alfresco.reindex.batchSize=100 \
--alfresco.reindex.concurrentProcessors=2 \
--spring.batch.datasource.url=jdbc:postgresql://localhost:5432/alfresco \
--spring.batch.datasource.username=springBatchUser \
--spring.batch.datasource.password=****** \
--spring.batch.datasource.driver-class-name=org.postgresql.Driver \
--spring.batch.drop.script=classpath:/org/springframework/batch/core/schema-drop-postgresql.sql \
--spring.batch.schema.script=classpath:/org/springframework/batch/core/schema-postgresql.sql
You don’t need to specify a job name for the worker because the configuration to use it is in the manager step context. This also means that you don’t need to restart a worker if the job name specified in the manager configuration changes.
The worker will not stop automatically because it is always up and running in order to wait for the new partition to index. The manager will automatically stop when all partitions have been indexed.
Batch Job Store DB
When using remote partitioning you are required to use a shared database that is accessible from all nodes. The database will contain the Batch job store. Spring batch will automatically create required tables, and those tables don’t contain sensitive data, so you can wipe them when required and you don’t need to back them up. It is recommended you use a unique database user to read the partition, and for managing the Spring batch. A list of supported databases can be retrieved, for more see Enum DatabaseType , and all available SQL initialization scripts are available, for more see spring-batch.
When using a different database you need to add to the Java classpath and to the right connection driver. The Re-indexing service is a Spring boot application which means you can’t add the JAR to the classpath, but instead you need to use a different command, for example:
java -cp alfresco-elasticsearch-reindexing-4.0.0-app.jar:mysql-connector-java-8.0.25.jar
-Dloader.main=org.alfresco.reindexing.ReindexingApp org.springframework.boot.loader.PropertiesLauncher
--alfresco.reindex.jobName=reindexByIds
--alfresco.reindex.partitioning.type=manager
--alfresco.reindex.fromId=0
--alfresco.reindex.toId=10000
--spring.batch.datasource.url=jdbc:mysql://localhost:3306/alfresco
--spring.batch.datasource.username=batchUser
--spring.datasource.username=batchUser
--spring.batch.datasource.password=*****
--spring.datasource.password=*****
--spring.batch.datasource.driver-class-name=com.mysql.jdbc.Driver
--spring.datasource.driver-class-name=com.mysql.jdbc.Driver
--spring.batch.drop.script=classpath:/org/springframework/batch/core/schema-drop-mysql.sql
--spring.batch.schema.script=classpath:/org/springframework/batch/core/schema-mysql.sql
From version 3.3.x you can use a different database, for more see Support for different databases.
Failures handling
If the manager** fails or a worker fails you can check which partitions were indexed in the log and launch them again by restarting the Re-indexing service.
Partition definition
The Re-indexing service creates partitions but only partitions the interval between the specified range, it is necessary to select the right range in order to avoid empty partitions. For instance, you can select the min and max values from the Alfresco database and then use those values in the configuration properties.
When re-indexing by ID range you can retrieve min and max values by executing the query below and using them for alfresco.reindex.fromId and alfresco.reindex.toId:
select min(id) as fromId, max(id) as toId from alf_node;
When re-indexing by date range you can retrieve min and max values by executing the query below and using them for alfresco.reindex.fromTime and alfresco.reindex.toTime:
select to_char(to_timestamp(min(commit_time_ms)/1000),'YYYYMMDDHHMI') as fromTime, to_char(to_timestamp(max(commit_time_ms)/1000),'YYYYMMDDHHMI') as toTime from alf_transaction;
It is easier to have unbalanced partitions when indexing by date range. Due to this it is recommended you use this strategy only when you are interested in indexing a specific date range. It is only recommended to perform a reindex by id range when you need to perform a full re-index.
Indexing only metadata
The Re-indexing application may be used to index only metadata. You can also exclude the content indexation from the process.
To apply this configuration, set the parameter alfresco.reindex.contentIndexingEnabled to false:
java -jar alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.contentIndexingEnabled=false
Indexing PATH property
By default, the re-indexing PATH property is disabled. To enable this feature, set the parameter alfresco.reindex.pathIndexingEnabled to true.
java -jar alfresco-elasticsearch-reindexing-4.0.0-app.jar \
--alfresco.reindex.pathIndexingEnabled=true
Enabling and disabling re-indexing features recommendations
By default the re-indexing application uses the following configuration:
alfresco.reindex.metadataIndexingEnabled=truealfresco.reindex.contentIndexingEnabled=truealfresco.reindex.pathIndexingEnabled=false
The re-indexing metadata process also indexes permissions associated with the document. This means when disabling metadata re-indexing, the content and path will not be updated for non-indexed documents. Only indexed documents will be updated with content and path.
The main use case to re-index only content or path is a fully metadata indexed repository that needs to update / complete the content or path.
Bulk metadata indexing
You can customize Search Enterprise by having the index ready with just the metadata of uploaded files or with the content of the files as well. If you have the content of your files indexed there are time and cost implications you must consider and it is only recommended when necessary. This example describes how to set up Search Enterprise to show the speed achievable when processing one billion files. Amazon Web Services have been used as the host but your setup will be specific to your requirements.
The configuration used in this example:
Search Enterprise Data Node
- AWS Elasticsearch
7.10with Availability Zone:1-AZ. - Number of Data Nodes:
3. - Instance Type:
r6g.2xlarge.search. - Storage type: EBS.
- EBS volume type: Provisioned IOPS (SSD).
- EBS volume size:
1000GBper node. - Fielddata cache allocation:
20. - Max clause count:
1024.
Indexing Instance
- Amazon EC2 Indexing instance to run
alfresco-elasticsearch-connector-distribution-3.2.1. - Indexing Instance type:
t2.2xlarge(8vCPUs,32GBRAM). - Number of Amazon EC2 Instances for Indexing:
3. - Number of threads running on instance 1 and 2 is
7each with6threads on instance 3. Total threads running in parallel is20. - Maximum Heap allocated to each thread is
4GB(-Xmx4G).
Search Enterprise Master Node
- Number of Master Nodes:
3. - Master Node instance type:
m5.large.search. - Master node is added for resilience, and can be avoided without having significant impact.
Search Enterprise Settings
- Number of Primary shards:
32. - Number of Replica shards:
0. - Refresh time: Disabled.
- Translog flush threshold:
2GB
Other Components
- Active MQ:
mq.m4.large. - RDS is used as the Database with
db.r5.2xlargerunning PostgreSQL. - Amazon EC2 Instance running Content Services and the Transform Service:
m5a.xlarge - Content Services:
7.2.0.
The deployment architecture of the system:
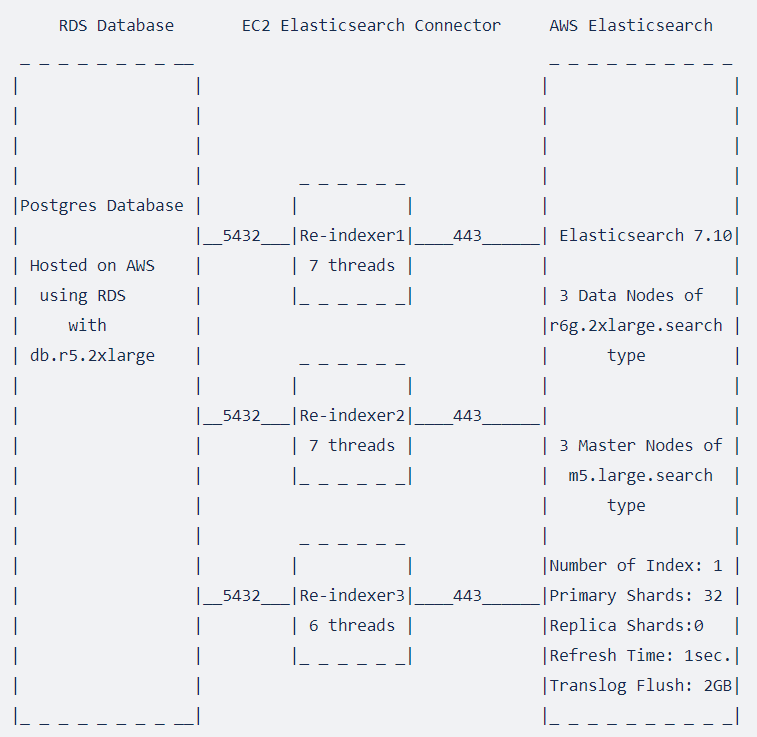
Configure Search Enterprise
Amazon Web Services recommend each shard should be not more than 50GB. For this example of one billion files the estimated total size of metadata to be indexed is 1.3TB. The shard size here can be set to 40GB which equals 32 shards.
On the same VPC set the number of shards:
curl -XPUT 'https://<Elasticsearch DNS>:443/alfresco?pretty' -H 'Content-Type: application/json' -d'
{
"settings" :{
"number_of_shards":32,
"number_of_replicas":0
}
}'
You can set other critical parameters such as the refresh interval and the translog flush threshold using curl. The refresh interval is the time in which indexed data is searchable and should be disabled. This is done by setting it to -1 or by setting it to a higher value during indexing to avoid the unnecessary usage of resources. The translog flush threshold is set to a higher size, for example 2GB, to avoid it periodically flushing during the indexing process.
To set the refresh interval to -1 to disable it:
curl -XPUT "https://<Elasticsearch DNS>:443/alfresco/_settings" -H 'Content-Type: application/json' -d '{ "index" : { "refresh_interval" : "-1" }}'
To set the translog flush threshold to 2GB:
curl -XPUT "https://<Elasticsearch DNS>:443/alfresco/_settings?pretty" -H 'Content-Type: application/json' -d '{"index":{"translog.flush_threshold_size" : "2GB"}}'
To verify the settings:
curl -XGET "https://<Elasticsearch DNS>:443/alfresco/_settings?pretty" -H 'Content-Type: application/json' -d '{ "index" : { "refresh_interval" }}'
To setup the Re-Indexing Instance:
-
Deploy three Amazon EC2 instances in the same VPC as all the other services.
-
Attach the Amazon EC2 instances to a security group that allows all incoming traffic from the other services.
-
Install Java 17 on all three instances.
-
Copy
alfresco-elasticsearch-connector-distribution-3.2.1to the three Amazon EC2 instances.Run
7threads on each of the two instances and6on the third instance to achieve a total of20thread count. -
In a command prompt on the VPC
cdto wherealfresco-elasticsearch-reindexing-3.1.1-app.jaris located. -
Run the following Indexing command with your specific configuration, where:
server.port- a unique port number to run the required number of threads needed for an instance. For example, to run 7 threads from instance one, you must copy the code 7 times and provide a unique port in each of the 7 sets of commands.alfresco.reindex.fromIdandalfresco.reindex.toId- a uniquenodeIDfor each thread. You can equally distribute the total file count among the threads. In this example, 1B among 20 threads with each thread receiving 50 million each. For example:- For Thread 1:
alfresco.reindex.fromId=0andalfresco.reindex.toId=50000000 - For Thread 2:
alfresco.reindex.fromId=50000001andalfresco.reindex.toId=100000000 - For Thread 3:
alfresco.reindex.fromId=100000001andalfresco.reindex.toId=150000000 - For Thread 20:
alfresco.reindex.fromId=950000001andalfresco.reindex.toId=1000000000
- For Thread 1:
Indexing Command:
nohup java -Xmx4G -jar alfresco-elasticsearch-reindexing-3.2.1-app.jar \
--server.port=<unique port> \
--alfresco.reindex.jobName=reindexByIds \
--spring.elasticsearch.rest.uris=https://<Elasticsearch DNS>:443 \
--spring.datasource.url=jdbc:postgresql://<DB Writer URL>:5432/alfresco \
--spring.datasource.username=**** \
--spring.datasource.password=**** \
--alfresco.accepted-content-media-types-cache.enabled=false \
--spring.activemq.broker-url=failover:\(ssl://<Broker 1>:61617,ssl://<Broker 2>:61617\) \
--spring.activemq.user=alfresco \
--spring.activemq.password=***** \
--alfresco.reindex.fromId=0 \
--alfresco.reindex.toId=50000000 \
--alfresco.reindex.multithreadedStepEnabled=true \
--alfresco.reindex.concurrentProcessors=30 \
--alfresco.reindex.metadataIndexingEnabled=true \
--alfresco.reindex.contentIndexingEnabled=false \
--alfresco.reindex.pathIndexingEnabled=true \
--alfresco.reindex.pagesize=10000 \
--alfresco.reindex.batchSize=1000 &
Indexing Speed
The table summarizes different indexing capabilities obtained with different data volumes but with identical infrastructure and configuration as outlined above.
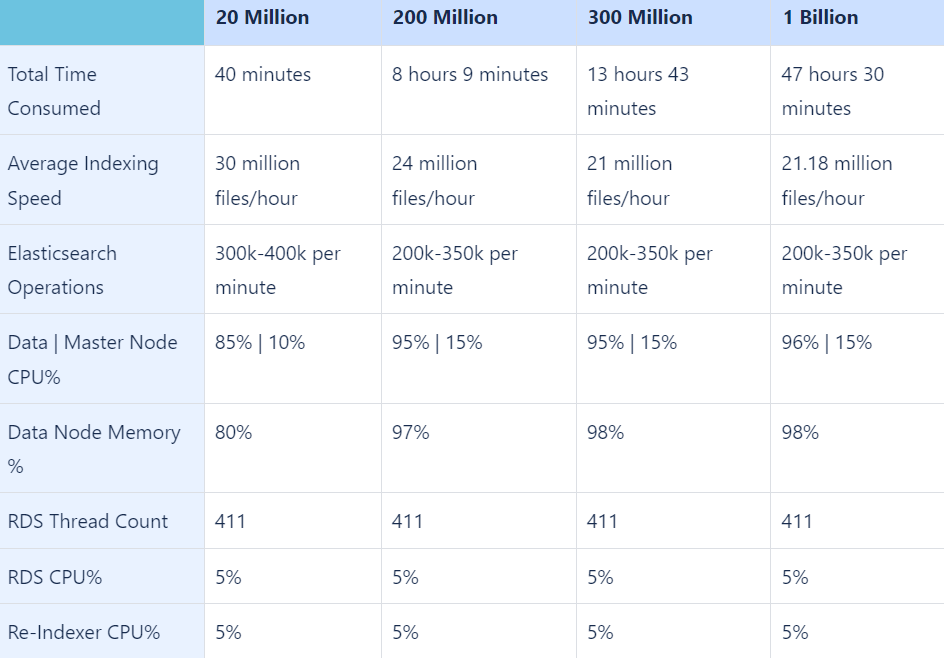
Search Enterprise Healthcheck
The Healthcheck allows you to check the status of the Search Enterprise index by sampling a configurable number of nodes. It does this by comparing the latest update for these nodes with the latest update for the equivalent database record. If these do not match, within a configurable tolerance, an error is reported. If you have nodes that have failed to index the Healthcheck provides a way of reindexing them. The Healthcheck can be run nightly to ensure that any updates in the last 24 hour period are up to date. Using the Healthcheck gives you confidence that all your repository content is searchable.
Configure Healthcheck in the Repository
The Alfresco Repository includes configuration properties for the Healthcheck. The property values are included in the alfresco-global.properties configuration file. To use these properties you must first activate the Search Enterprise Subsystem, for more see Configure Subsystem in Repository. You can also use the JConsole to configure the Healthcheck.
| Property | Description |
|---|---|
| elasticsearch.healthcheck.id.minRange | The minimum healthcheck database node ID. A node must have a database ID greater than or equal to the specified value that is included in the healthcheck. |
| elasticsearch.healthcheck.id.maxRange | The maximum healthcheck database node ID. A node must have a database ID that is less than or equal to the specified value that is included in the healthcheck. |
| elasticsearch.healthcheck.date.minRange | The minimum healthcheck database node update date. A node must have a database update date that is greater than or equal to the specified value that is included in the healthcheck. The default is 2023-01-01T23:59:00Z. |
| elasticsearch.healthcheck.date.maxRange | The maximum healthcheck database node update date. A node must have a database update date that is less than or equal to the specified value that is included in the healthcheck. The default is 2023-01-07T23:59:00Z. |
| elasticsearch.healthcheck.batchSize | The number of nodes aggregated from the database to be checked in Search Enterprise in one go. The property cannot be greater than 10000. The default is 10000 |
| elasticsearch.healthcheck.confidenceThresholdInMs | A threshold value in milliseconds that can be used to help you avoid false positives. It can be used in cases where the timestamp difference between the database and Search Enterprise is below the threshold. An example of this is when you are managing out of order events, or in circumstances where you have expected delays in indexing. The default is 1000. |
| elasticsearch.healthcheck.pollingRatio | The distance between nodes to check. For example, if you set this property to 10, then every 10th node within the configured range is checked. The default is 1. |
| elasticsearch.healthcheck.timeoutInHours | The number of hours the healthcheck is allowed to run. If the time out is exceeded, the healthcheck is stopped and only the results found until the healthcheck is stopped will be displayed. The default is 1. |
| elasticsearch.healthcheck.startTime | The scheduled time to automatically start the healthcheck. The default is 2030-12-30T23:59:00Z. |
| elasticsearch.healthcheck.intervalPeriod | The period of time the healthcheck should wait between repeated executions after the first scheduled execution. The possible values are: Month, Week, Day, Hour, Minute, or Second. The default is Week. |
| elasticsearch.healthcheck.intervalCount | Sets how many periods should be waited between each scheduled execution. The default is 1. |
| elasticsearch.healthcheck.nodeAspectsToExclude | A comma-separated list of node aspects. Nodes with any of the aspects from the specified list will be excluded from the healthcheck. The default is sys:hidden. |
Note: You can only set one range format, either ID or Date. This means two properties for one of the range formats must always be empty.
Run Healthcheck Job
Use the JConsole to run the Healthcheck.
Note: The MBean
Alfresco:Name=ElasticsearchHealthcheckis exposed and allows you to manage the Healthcheck.
-
Open a command prompt and
cdto your JDK installation directory. -
Open the Java Monitoring & Management Console window by entering:
jconsole. -
Double click the Alfresco Content Services Java process.
The JConsole connects to the managed bean, or MBean server hosting the subsystems. For Tomcat, the Java process is labelled:
org.apache.catalina.startup.Bootstrap start. -
Select the MBeans tab.
The available managed beans are displayed in the console.
-
Navigate to Alfresco > ElasticsearchHealthcheck > Operations.
-
Select one of the following:
triggerHealthcheckJobs()- run Healthcheck immediately.scheduleHealthcheckJob()- schedule a healthcheck job, according to theelasticsearch.healthcheck.startTimeandelasticsearch.healthcheck.intervalPeriodproperties.unscheduleHealthcheckJob()- unschedule a Healthcheck job.
The Healthcheck Job results
-
Open the Admin Console, for more see Launch Admin Console.
-
In the Repository Services section, click Search Service.
-
Select the Service Status tab.
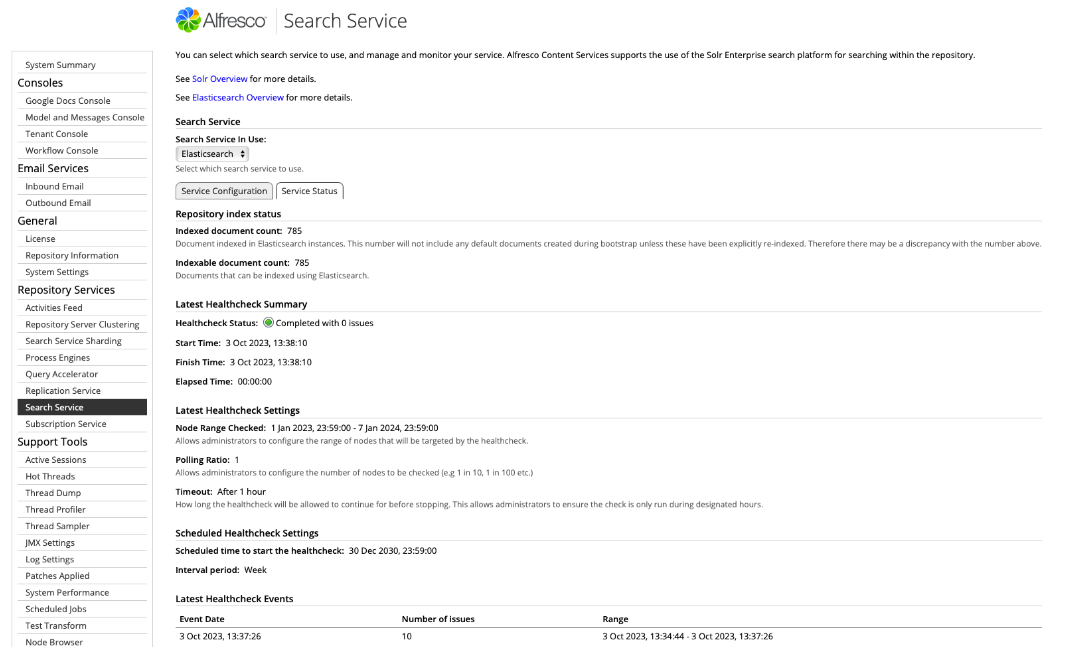
The Service Status tab gives information on the status of the latest Healthcheck execution, latest healthcheck settings, and scheduled healthcheck settings. At the bottom of the page there is a list of the latest Healthcheck events sorted by date. You can see ranges of nodes where discrepancies in the indexing were found. This means the range starts immediately after the previous correctly indexed node and finishes immediately before the first next correctly indexed node. You can also see the number of issues found within each range.
Logging
You will see a similar output if the Healthcheck has completed and some issues were found:
2023-10-11 12:57:15 2023-10-11T10:57:15,693 [] INFO [validator.job.ElasticsearchValidationActionExecutor] [pool-14-thread-1] The Elasticsearch healthcheck job finished with 642 issues in 2 ranges.
You will see a similar output if the Healthcheck is completed without any issues being found:
2023-10-11 11:40:01 2023-10-11T09:40:01,786 [] INFO [validator.job.ElasticsearchValidationActionExecutor] [pool-16-thread-1] The Elasticsearch healthcheck job finished with no issues.
You can obtain detailed logs for the Healthcheck that provide all ranges of information to do with any issues according to the current Healthcheck execution. You do this by activating the TRACE level for the org.alfresco.repo.search.impl.elasticsearch.admin.validator.job.ElasticsearchValidationActionExecutor class, for more see Set log levels.
You will see a similar output:
2023-10-11 12:57:15 2023-10-11T10:57:15,548 [] DEBUG [validator.job.ElasticsearchValidationActionExecutor] [pool-14-thread-1] The Elasticsearch healthcheck job started.
2023-10-11 12:57:15 2023-10-11T10:57:15,690 [] TRACE [validator.job.ElasticsearchValidationActionExecutor] [pool-14-thread-1] The Elasticsearch healthcheck job found 638 discrepancies in date range (2023-10-11T10:50:02.124Z, 2023-10-11T10:50:28.395Z)
2023-10-11 12:57:15 2023-10-11T10:57:15,690 [] TRACE [validator.job.ElasticsearchValidationActionExecutor] [pool-14-thread-1] The Elasticsearch healthcheck job found 4 discrepancies in date range (2023-10-11T10:56:10.164Z, 2023-10-11T10:57:15.519Z)
2023-10-11 12:57:15 2023-10-11T10:57:15,693 [] INFO [validator.job.ElasticsearchValidationActionExecutor] [pool-14-thread-1] The Elasticsearch healthcheck job finished with 642 issues in 2 ranges.