This gives an introduction to the Content Services architecture from a developer’s perspective. At its core is a repository that provides a store for content, and a wide range of services that can be used by content applications to manipulate the content.
The following diagram illustrates the three main components that the Content Services consists of. The Platform, the User Interface (UI), and the Search engine. These components are implemented as separate web applications:

The main component is called the Platform and is implemented in the alfresco.war web application. It provides the
repository where content is stored plus all the associated content services. Alfresco Share provides a web client
interface (that is a User Interface, UI) for the repository and is implemented as the share.war web application.
Share makes it easy for users to manage their sites, documents, users and so on. The search functionality is implemented
on top of Apache Solr 4 and provides the indexing of all content, which enables powerful search functionality.
There are also mobile clients that will access the content via ReST APIs provided by the platform.
Most Content Services projects will implement a domain specific web client based on the Alfresco Application Development Framework (ADF). It gives you full freedom to design a content and process web client supporting exactly the use cases needed by the domain. Giving the end-users the best possible experience.
The Platform and UI components run in the same Apache Tomcat web application server. The Search component runs in its own Jetty web application server. The Platform is usually also integrated with a Directory Server (LDAP) to be able to sync users and groups with Content Services. And most installations also integrates with an SMTP server so the Platform can send emails, such as site invitations.
The Platform also contains numerous APIs, such as the Java foundation API and the ReST API.
Alfresco provides a number of extension points to allow you to customize Content Services. These extensions points have various formats, but include:
- Platform extension points and detailed architecture
- Share extension points and detailed architecture
- ReST API.
- Public Java API
Content repository concepts
It is important as a developer to have a good understanding of the fundamental concepts of Content Services when implementing extensions. It is vital to know what things such as repository, node, store, type, aspect, association and so on mean in the context of Content Services.
Overview
The repository is comparable to a database, except that it holds more than data. The actual binary streams of the content are stored in files managed in the repository, although these files are for internal use only and don’t reflect what you might see through the user interfaces. The repository also holds the associations among content items, classifications, and the folder/file structure. The folder/file structure is maintained in the database and is not reflected in the internal file storage structure.
The repository implements services including:
- Definition of content structure (modeling)
- Creation, modification, and deletion of content, associated metadata, and relationships
- Query of content
- Access control on content (permissions)
- Versioning of content
- Content renditions
- Locking
- Events
- Audits
- Import/Export
- Multilingual
- Rules/Actions
The repository implements and exposes these services through an Alfresco ReST API and CMIS protocol bindings. The storage engine of the repository stores and retrieves content, metadata, and relationships.
Key Concepts
All files that are stored in Content Services are stored in what is referred to as the repository. The repository is a logical entity that consists of three important parts:
- The physical content files that are uploaded, which are stored in the file system.
- The index files created when indexing the uploaded file so it is searchable, which are managed by an external Apache Solr server.
- The metadata/properties for the file, which are stored in a relational database management system (RDBMS).
When a file is uploaded to the repository it is stored on disk in a special directory structure that is based on the date and time of the upload. The file name is also changed to the UUID (Universally Unique Identifier) assigned to the file when it is added to the repository. The file’s metadata is stored in an RDBMS such as PostgreSQL. Indexes are also stored on the disk. When the file is added to the repository it is stored in a folder, and the folder has domain specific metadata, rules, and fine grained permissions. The top folder in the repository is called Company Home, although it will be referred to with the name repository in the Alfresco Share user interface.
When a file is uploaded to the repository it is always classified according to a so called content model. A content model is one of the first things that will be designed and implemented in a content management project. It customizes the repository to store information for a specific domain, such as healthcare, finance, manufacturing, legal etc. By classifying content (i.e. files and folders) end users can search and process content more effeciently.
Logical Structure
All the files and folders that are uploaded and created in the repository are referred to as nodes. Some nodes, such as folders and rules, can contain other nodes (and are therefore known as container nodes). Nodes can also be associated with other nodes in a peer to peer relationship, in a similar fashion to how an HTML file can reference an image file. All nodes live in a Store. Each store has a root node at the top, and nodes can reference specific files, as shown in the following diagram:

Stores Overview
The Repository contains multiple logical stores. However, a node lives only in one store. Most of the stores are implemented as data in the connected RDBMS, only the Content Store is implemented so as to store items on disk:

The main stores
- The Working Store (
workspace://SpacesStore) contains the metadata for all active/live nodes in the Repository. This store is implemented using a database (RDBMS). - The Content Store contains the physical files uploaded to the Repository and is located in the
{Alfresco install dir}/alf_data/contentstoredirectory on the filesystem by default, but can also be configured to use other storage systems, for example, Amazon S3. It is also possible to define content store policies for storing files on different storage systems, effectively defining more than one physical content store. - Whenever a node is deleted, the metadata for the node is moved to the Archive Store (
archive://SpacesStore), which uses the configured database. The physical file for a deleted node is moved (by default after 14 days) to the{Alfresco install dir}/alf_data/contentstore.deleteddirectory, where it stays indefinitely. However, a clean-up job can be configured to remove the file at a certain point in time (referred to as eager clean-up). - When the
versionableaspect is applied to a node, a version history is created in the Version Store (workspace://version2Store). Versioned node metadata is stored in the database and files remain in the{Alfresco install dir}/alf_data/contentstoredirectory. Versioning is not applicable to folder nodes. - The System Store is used to save information about installed Alfresco Content Services extension modules.
Content Store Implementation
When considering file storage, it should be noted that files added to Content Services can be of almost any type, and include images, photos, binary document files (Word, PPT, Excel), as well as text files (HTML, XML, plain text). Some binary files such as videos and music files can be relatively large. Content store files are located on the disk, rather than in the database as BLOBs. There are several reasons for this:
- It removes incompatibility issues across database vendors.
- The random file access support cannot be provided by database persistence without first copying files to the file system.
- Possibility of real-time streaming (for direct streaming of files to browser).
- Standard database access would be difficult when using BLOBs as the most efficient BLOB APIs are vendor-specific.
- Faster access.
Content Store Selectors
The content store selector provides a mechanism to control the physical location on disk for a content file associated with a particular content node. This allows storage polices to be implemented to control which underlying physical storage is used, based on your applications needs or business policies.
For example, it is possible to use a very fast tier-1 Solid State Drive (SSD) for our most important content files. Then, based on business policies that have been decided, gradually move the data, as it becomes less important, to cheaper tier-2 drives such as Fiber Channel (FC) drives or Serial ATA drives. In this way, it is possible to manage the storage of content more cost effectively:

Store Reference
When working with the APIs a store is accessed via its store reference, for example workspace://SpacesStore. The
store reference consists of two parts: the protocol and the identifier. The first part (for example workspace) is called
the protocol and indicates the content you are interested in, such as live content (workspace://SpacesStore) or
archived content (archive://SpacesStore). The second part is the identifier (the type of store) for the store, such as
SpacesStore, which contains folder nodes (previously called spaces) and file nodes data, or for example
lightWeightVersionStore that contains version history data.
Important: The reason some things are referred to as spaces (for example SpacesStore) is that in previous versions of Content Services a folder used to be called a space. The Share user interface has generally been changed to use the name folder instead of the name space. However, there is functionality, such as Space Templates, that still uses the term “space”. A space can simply be thought of as a folder.
Node Information
A node usually represents a folder or a file. Each store also contains a special root node at the top level with the type
sys:store_root. The root node can have one or more child nodes, such as the Company Home folder node. Each node has a
primary path to a parent node and the following metadata:
- Type: a node is of one type, such as Folder, File, Marketing Document, Rule, Calendar Event, Discussion, Data List and so on.
- Aspects: a node can have many aspects applied, such as Versioned, Emailed, Transformed, Classified, Geographic and so on.
- Properties: both types and aspects define properties. If it is a file node then one of the properties points to the physical file in the content store.
- Permissions: access control settings for the node.
- Associations: relationships to other nodes (peer or child).
Node Reference
A node is uniquely identified in the Repository via its node reference, also commonly referred to as NodeRef.
A node reference points to a store and a node in that store. A node reference has the following format:
{store protocol://store identifier}/UUID such as for example workspace://SpacesStore/986570b5-4a1b-11dd-823c-f5095e006c11.
The first part is the store reference and the second part is a Universally Unique Identifier (UUID) for that store.
Node references are used a lot in the available APIs so it is good to have an idea of how they are constructed.
Node Properties
The node properties, also referred to as the node’s metadata, contains the majority of the information for a node.
The sys:store-protocol, sys:store-identifier, and sys:node-uuid properties contains all the data needed to
construct the NodeRef, uniquely identifying the node. The special property called cm:content points to where the
physical content file is stored on disk (unless it is a folder or other contentless node type). All properties are
either contained in a type or in an aspect defined in a content model. When a node is created some properties are
automatically set by the system and cannot be easily changed, they are called audit properties
(from the cm:auditable aspect) and are Created Date, Creator, Modified Date, Modifier, and Accessed. Defining new
domain specific node properties, together with the types and aspects that contain them, is the primary way of classifying
a node so it can be easily found via searches.
Metadata/Property Extractors
Some of the properties of a file node are set automatically when it is uploaded to the Repository, such as author. This is handled by metadata extractors. A metadata extractor is set up to extract properties from a specific file MIME type. There are numerous metadata extractors available out-of-the-box covering common MIME types such as MS Office document types, PDFs, Emails, JPEGs, HTML files, DWG files and more. The metadata extractors are implemented via the Tika library, although custom metadata extractors are available. Each metadata extractor implementation has a mapping between the properties it can extract from the content file, and what content model properties that should be set as node metadata.
Node Associations
There are two types of associations:
- Parent to Child associations - these are for example folder to file associations where deleting the folder will cascade delete its children.
- Peer to Peer - an example could be article to image associations where deleting the article does not affect the related image node(s). These associations are also referred to as source to target associations.
QName
All properties are defined within a specific content model, which also defines a unique namespace. For example, a
property called description can be part of many namespaces (content models). To uniquely identify what description
property is being referenced, a fully qualified name, or a QName, is used. A QName has the following format:
{namespace URL}property local name, for example:
{http://www.alfresco.org/model/content/1.0}description
The first part in curly braces is the namespace identifier defining the content model that the property is part of. The second part is the local name of the property (that is description in this case).
A QName is used for types, aspects, properties, associations, constraints and so on. The QName for the generic folder
type that is part of the out-of-the-box document content model is cm:folder. Note the use of cm to denote the namespace.
Each content model defines a prefix for each namespace that is used in the content model. Each type, aspect, property
and so on in the content model definition uses the namespace prefix instead of the full namespace URL. You will also
use the prefix when referring to entities such as types, aspects, properties, in the different APIs.
Permissions
Permissions are set up per node and a node can inherit permissions from its parent node. A Role (Group) Based Access Control configuration is the preferred way to set up permissions in the repository. However, permissions can also be set for an individual user. Groups and users can be synchronized with an external directory such as LDAP or MS Active Directory. Some groups are created automatically during installation:
- EVERYONE – all users in the system
- ALFRESCO_ADMINISTRATORS – administrators with full access to everything in the Repository.
- ALFRESCO_SEARCH_ADMINISTRATORS – can access the Search Manager tool and set up search filters (facets).
- SITE_ADMINISTRATORS – can access the Site Manager tool and change visibility of sites, delete sites, and perform site related operations.
- E-MAIL_CONTRIBUTORS – users that can send email with content into Alfresco Content Services.
Permission settings involve three entities:

There are a number of out-of-the-box roles:
- Consumer
- Contributor
- Editor
- Collaborator
- Coordinator
Whenever a Share site is created there are also four associated groups created that are used to set up permissions
within the site. In the repository, groups are prefixed with GROUP_ and roles with ROLE_, this is important when
referring to a group or role when using one of the APIs.
Important: A Site is a collaboration area in Alfresco Share where a team of people can collaborate on content.
Owner
The Repository contains a special authority called owner. Whoever creates a node in the repository is called the owner
of the node. Owner status overrides any other permission setting. As owner you can do any operation on the node
(basically the same as being coordinator/admin). Anyone with Coordinator or Admin status can take ownership of a node
(cm:ownable is then applied).
Folder Node and File Node Overview
The diagram illustrates a typical folder node with a child file node when it has been classified with the out-of-the-box default document content model:

System overview
At the core of the Content Services system is a repository supported by a server that persists content, metadata, associations, and full text indexes. Programming interfaces support multiple languages and protocols upon which developers can create custom applications and solutions. Out-of-the-box applications provide standard solutions such as document management and records management.
The Content Services system is implemented in Java, which means that it can run on most servers that can run the Java Standard Edition. The platform components have been implemented using the Spring framework, which provides the ability to modularize functionality, such as versioning, security, and rules. The platform provides a scripting environment to simplify adding new functionality and developing new programming interfaces. This portion of the architecture is known as Web Scripts and can be used for both data and presentation services. The lightweight architecture is easy to download, install, and deploy.
Ultimately, Content Services is used to implement ECM solutions, such as document management and records management. There can also be elements of collaboration and search across these solutions.
A content management solution is typically divided into clients and a server. The clients offer users a user interface to the solution and the server provides content management services and storage. Solutions commonly offer multiple clients against a shared server, where each client is tailored for the environment in which it is used.
Clients
Content Services offers a web-based client called Alfresco Share, built entirely with the web script technology. Share provides content management capabilities with simple user interfaces, tools to search and browse the repository, content such as thumbnails and associated metadata, previews, and a set of collaboration tools such as wikis and discussions. Share is organized as a set of sites that can be used as a meeting place for collaboration. It’s a web-based application that can be run on a different server to the server that runs the platform with repository, providing opportunities to increase scale and performance.
Alfresco has offered the Share web client for a long time. However, if a content management solution requires extensive customization to the user interface, which most do, then it is not recommended to customize Share. Develop instead a custom client with the Alfresco Application Development Framework (ADF), which is Angular based and uses the public ReST API behind the scenes.
Clients also exist for mobile platforms, Microsoft Outlook, Microsoft Office, and the desktop. In addition, users can share documents through a network drive via WebDAV.
Server
The content application server comprises a content repository, value-added services, extension points, and a ReST API for building solutions.
The content application server provides the following categories of services built upon the content repository:
- Content services (node management, transformation, tagging, metadata extraction)
- Control services (workflow, records management, change sets)
- Collaboration services (calendar, activities, wiki)
Clients communicate with the content application server and its services through a ReST API and numerous other supported protocols, such as FTP, WebDAV, IMAP, and Microsoft SharePoint protocols.
The server side repository with its services is also referred to as the platform.
Platform architecture
The platform architecture consists of the repository and related services. The platform contains the key extension points for building your own extensions.
The following diagram illustrates the platform architecture and extension points. Note that this does not represent a complete list of extension points:
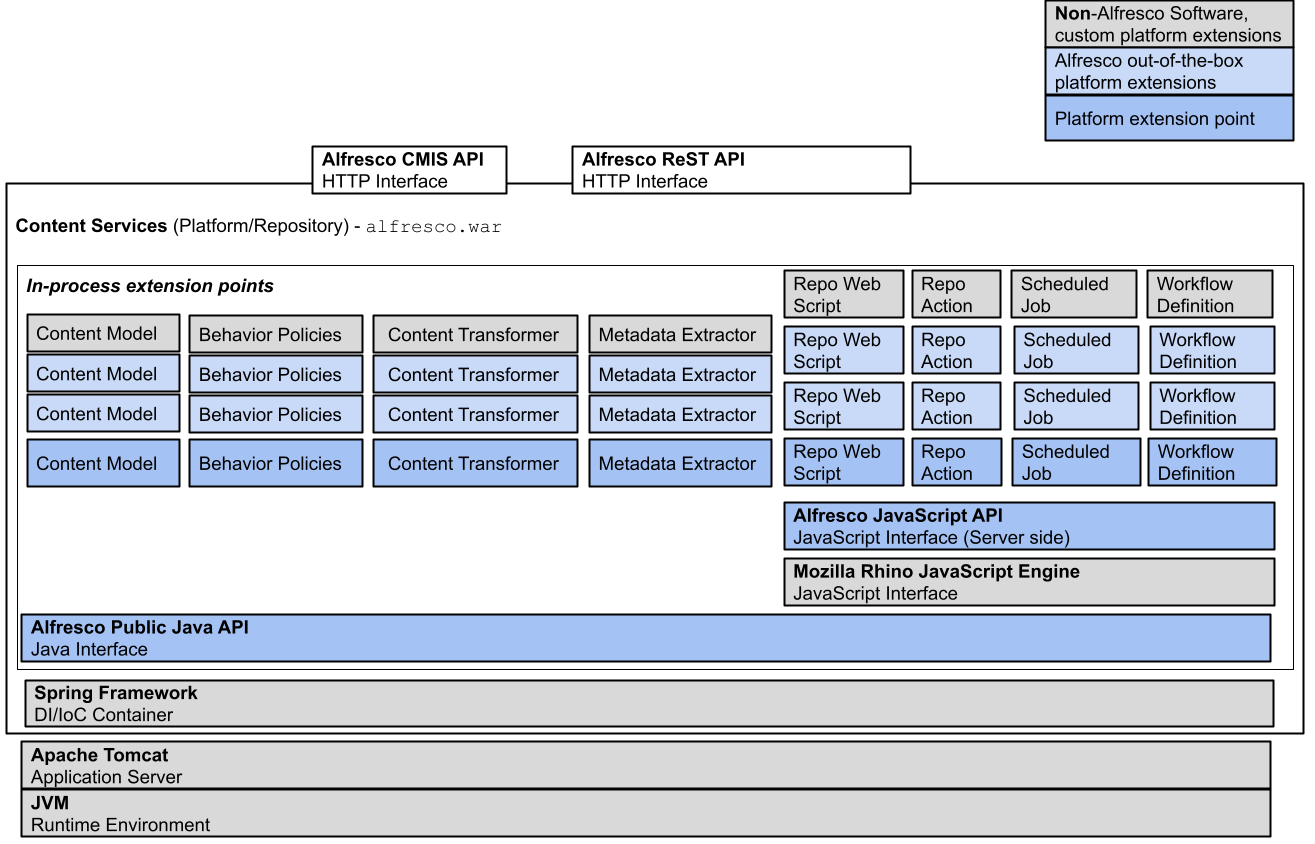
The platform consists of the repository and all services, developer extension points, and APIs, such as the ReST API. The repository provides storage for documents and other content. The content metadata is stored in a relational database, while the content itself is stored directly on the file system. The relationships between content items, and their various properties (metadata) are defined in one or more content models.
Content models can be thought of as describing types of content and the relationships between pieces of content. For example, there is a relationship between a content that has a container functionality (that is, folder), and the piece of content contained within it (that is, sub-folders and files). There might be constraints defined in the content model, such as a content type cannot contain other content unless it is a container type.
As well as the basic content storage functionality, the platform provides a wide range of content-related services. These include core services such as the Node Service, and the Version Service. There are also higher-level services such as Thumbnail Service (for creating thumbnail images and renditions of documents), the Site Service used for creating and managing sites in the Share application, and the Tagging Service, which provides the ability to tag content with keywords. The following sections of this documentation provide a brief tour of the available services.
Typically these services are implemented in Java, and expose an API described by the Public Java API.
The platform is highly extensible. You can write extensions in Java, JavaScript, and FreeMarker, and you can write client applications in any language using the ReST API. You can create new content models that define new content types, metadata, and relationships. You can define custom actions that the repository will carry out when certain events happen (such as when new content is added to the repository). You can even create entirely new services, if required.
When you need to create custom business workflow you should use the Alfresco Process Services (APS) product.
Content modeling
Content modeling is a fundamental building block of the repository that provides a foundation for structuring and working with content.
Content modeling specifies how nodes stored in the repository are constrained, imposing a formal structure on nodes that an application can understand and enforce. Nodes can represent anything stored in the repository, such as folders, documents, XML fragments, renditions, collaboration sites, and people. Each node has a unique ID and is a container for any number of named properties, where property values can be of any data type, single or multi-valued.
Nodes are related to each other through relationships. A parent/child relationship represents a hierarchy of nodes where child nodes cannot outlive their parent. You can also create arbitrary relationships between nodes and define different types of nodes and relationships.
A content model defines how a node in the repository is constrained. Each model defines one or more types, where a type enumerates the properties and relationships that a node of that type can support. Often, concepts that cross multiple types of node must be modeled, which the repository supports through aspects. Although a node can only be of a single type, you can apply any number of aspects to a node. An aspect can encapsulate both data and process, providing a flexible tool for modeling content.
Content modeling puts the following constraints on the data structure:
- A node must be of a given kind.
- A node must carry an enumerated set of properties.
- A property must be of a given data type.
- A value must be within a defined set of values.
- A node must be related to other nodes in a particular way.
These constraints allow the definition (or modeling) of entities within the domain. For example, many applications are built around the notion of folders and documents. It is content modeling that adds meaning to the node data structure.

The repository provides services for reading, querying, and maintaining nodes. Events are fired on changes, allowing for processes to be triggered. In particular, the repository provides the following capabilities based on events:
- Policies: event handlers registered for specific kinds of node events for either all nodes or nodes of a specific type
- Rules: declarative definition of processes based on addition, update, or removal of nodes (for example, the equivalent of email rules)
Models also define kinds of relationships, property data types, and value constraints. A special data type called content
allows a property to hold arbitrary length binary data. Content Services comes prepackaged with several content models.
You can define new models for specific use cases from scratch or by inheriting definitions from existing models.
For more information see content model introduction.
Access protocols
Content Services supports a number of different protocols for accessing the content repository. Their availability extends the options available to developers, when building their own applications and extensions.
Protocols provide developers with another possible avenue for building their own applications and extensions. For example, if you are building a client application to connect with multiple repositories from multiple vendors, including Content Services, then CMIS is a consideration. If you are building a client to connect via the SharePoint Protocol, then use the Alfresco Office Services (AOS). Protocols provide a resource for developers, in addition to the numerous other extension points and APIs built into Alfresco.
When any of these protocols are used to access or upload content to the repository, access control is always enforced based on configured permissions, regardless of what protocol that is used.
The following table list some of the main protocols supported by Content Services:
| Protocol | Description | Support Status |
|---|---|---|
| HTTP | The main protocol used to access the repository via for example the ReST APIs. | Standard in Content Services and Community Edition. |
| WebDAV | Web-based Distributed Authoring and Versioning is a set of HTTP extensions that lets you manage files collaboratively on web servers. It has strong support for authoring scenarios such as locking, metadata, and versioning. Many content production tools, such as the Microsoft Office suite, support WebDAV. Additionally, there are tools for mounting a WebDAV server as a network drive. | Standard in Content Servicesand Community Edition. |
| FTP | File Transfer Protocol - standard network protocol for file upload, download and manipulation. Useful for bulk uploads and downloads. | Standard in Content Services and Community. |
| Alfresco Office Services | Alfresco Office Services (AOS) allow you to access Content Services directly from all your Microsoft Office applications. | Standard in Content Services and Community Edition. |
| CMIS | Alfresco fully implements both the CMIS. 1.0 and 1.1 standards to allow your application to manage content and metadata in an on-premise repository. | Standard in Content Services and Community Edition. |
| IMAP | Internet Message Access Protocol - allows access to email on a remote server. Content Services can present itself as an email server, allowing clients such as Microsoft Outlook, Thunderbird, Apple Mail and other email clients to access the content repository, and manipulate folders and files contained there. IMAP supports three modes of operation: 1. Archive: allows email storage in the repository by using drag/drop and copy/paste from the IMAP client.2. Virtual: folders and files held in the repository are exposed as emails within the IMAP client with the ability to view metadata and trigger actions using links embedded in the email body.3. Mixed: a combination of both archive and virtual. |
Standard in Content Services and Community Edition. |
| SMTP | It is possible to email content into the repository (InboundSMTP). A folder can be dedicated as an email target. | Standard in Content Services and Community Edition. |
All the protocol bindings expose folders and documents held in the repository. This means a client tool accessing the repository using the protocol can navigate through folders, examine properties, and read content. Most protocols also permit updates, allowing a client tool to modify the folder structure, create and update documents, and write content. Some protocols also allow interaction with capabilities such as version histories, search, and tasks.
Internally, the protocol bindings interact with the repository services, which encapsulate the behavior of working with folders and files. This ensures a consistent view and update approach across all client tools interacting with the content application server.
A subsystem for file servers allows configuration and lifecycle management for each of the protocols either through property files or JMX.
Modularity
The Content Services system is modular. Every moving part is encapsulated as a service, where each service provides an external face in a formally defined interface and has one or more black-box implementations.
The system is designed this way to allow for:
- Pick and mix of services for building an ECM solution
- Reimplementation of individual services
- Multiple implementations of a service, where the appropriate implementation is chosen based on the context within which the solution is executed
- A pattern for extending Content Services (at design and runtime)
- Easier testing of services
To support this approach, Content Services used the Spring framework for its factory, Dependency Injection, and Aspect-Oriented Programming (AOP) capabilities. Services are bound together through their interfaces and configured using Spring’s declarative Dependency Injection:

A service interface is defined as a Java interface. For services that form the internal embedded API for extensions, cross-cutting concerns such as transaction demarcation, access control, auditing, logging, and multi-tenancy are plugged in through Spring AOP behind the service interface. This means that service implementations are not polluted with these concerns. It also means the cross-cutting concerns can be configured independently or even switched off across the server if, for example, performance is the top-most requirement and the feature is not necessary.
Multiple services are aggregated into an Content Services subsystem where a subsystem represents a complete coherent capability of the Content Services server, such as authentication, transformation, and protocols. As a unit, subsystems have their own lifecycle where they can be shut down and restarted while the server is running. This is useful to disable aspects of the server, or reconfigure parts of it, such as how LDAP synchronization is mapped. Each subsystem supports its own administration interface that is accessible through property files or JMX.
Web UI architecture
The Web UI architecture consists of a number of web clients and the Application Development Framework (ADF).
This section covers the Web UI architecture in detail. There are a number of web clients available when accessing the repository. There is also the Application Development Framework that can be used to build domain specific web applications.
Application development architecture
This section gives an overview of the Alfresco application development architecture. It covers the Application Development Framework (ADF) and the Alfresco JavaScript framework.
Alfresco has traditionally always offered a Web client called Share, which is still available. However, if a content management solution requires extensive customization to its user interface, which most do, then it is not recommended to customize Share. Develop instead a custom client with the Alfresco Application Development Framework, which is Angular based.
Application Development Framework (ADF)
This section gives an introduction to the Alfresco Application Development Framework (ADF), which is used to build custom domain specific Web UIs that should manage content and processes in the Alfresco content repository.
Overview
The Alfresco Application Development Framework, referred to as ADF, is built on top of the Angular JavaScript framework. You can think of ADF as a library of Alfresco web components that can be used to build a content management web application and/or a process management web application.
There are a number of web components that you can use to integrate your web application with Content Services (ACS). Here are some of these components:
- Folder Hierarchy Breadcrumbs - display a breadcrumb with clickable folder path
- Document List - list folders and files
- Search - search folders and files
- Tag - manage and list tags
- Upload - upload files via button or drag-and-drop
- Viewer - preview files in the browser
- Webscript - call a Web Script (i.e. a ReST call)
And for integrating with Alfresco Process Services (APS) you have the following components:
- Analytics - display graph reports such as process instance overview
- Diagram - show process definition diagram, if associated with running process instance then the activities are highlighted according to their state
- Process Apps - shows a list of process applications
- Process List - show a list of process instances
- Process Details - multiple components are available to show different details for a process
- Task List - show a list of task instances for a process instance(s)
- Task Details - multiple components are available to show different details for a task
There are also a number of generic components that are used with both ACS and APS:
- Breadcrumbs - indicates the current position within a navigation hierarchy
- Toolbar - an extension to the Angular Material toolbar with a title and color
- Accordion - creates a collapsible accordion menu
- Card View - displays properties in a nice layout
- Data Table - generic data table implementation that is used by, for example, Document List
- Drag-and-Drop - Drag and drop files into for example a folder
- Form - display properties from nodes, tasks, and other sources in a form defined in JSON
- Login - authenticates with both services
- User Info - display information about a user
For a complete list of all components with documentation see the ADF Component Catalogue .
Architecture
These ADF components don’t talk directly to the ACS and APS backend services. There are some layers between them that are worth knowing about before you start coding. The ADF components talk to ADF services, which in turn talks to the Alfresco JS API , which internally calls ACS and APS via their respective ReST APIs. You could use the both the ADF services and the Alfresco JS API directly from your application if there is no ADF component available to do what you want. In fact, you will quite frequently have to use the ADF services in your application to fetch content nodes, process instances, task instances etc.
The following picture illustrates the architecture of an ADF solution:

The ADF components and services are implemented in Angular, which in turn is implemented in TypeScript. The Alfresco JavaScript library is pure JavaScript and could be used with any other JavaScript framework.
Application Generator
There is an ADF application generator that can be very useful if you just want to quickly get going with an ADF project, such as for a demo or proof-of-concept scenario. It covers use cases for both ACS and APS. It can be used to generate the following types of ADF applications:
- ADF Content Management App (use this template if your app is only going to talk to ACS)
- ADF Process Management App (use this template if your app is only going to talk to APS)
- ADF Content and Process Management App
Using the App Generator is simple. Install the Yeoman tool. Then install the App Generator as follows:
$ sudo npm install generator-alfresco-adf-app -g
Password:
+ generator-alfresco-adf-app@2.3.0
added 243 packages in 5.438s
Running the generator is easy:
$ yo
? 'Allo Martin! What would you like to do? (Use arrow keys)
Run a generator
❯ Alfresco Adf App
──────────────
Update your generators
Install a generator
Find some help
Clear global config
Select the ‘Alfresco Adf App’ generator and follow instructions.
Alfresco JavaScript API
This page gives an introduction to the Alfresco JavaScript API, which can be used from any third party JavaScript library.
The Alfresco JavaScript API is not normally used directly. Instead the Alfresco Application Development Framework (ADF) is used, which uses the JavaScript API indirectly. But there are situations when it might be necessary to use the JavaScript API directly, such as when ADF cannot be used. ADF is based on Angular and if another JavaScript library such as React has been adopted, then it is beneficial to use the Alfresco JavaScript API directly from React.
The Alfresco JavaScript library abstracts the Content Services (ACS) ReST API and the Alfresco Process Services (APS) ReST API, so a lot of work has been done to make it smooth to use the Alfresco ReST APIs from a third party JavaScript library. For example, authentication with both ACS and APS is handled automatically by the Alfresco JavaScript library.
For more information about the Alfresco JavaScript API, and examples of how to use it, have a look here.
Share Web Client architecture
When developing for Share it is important to understand the application architecture and the underlying development frameworks. It is also important to know what extension points that are available to you for customizing the UI in a supported way.
Introduction
Alfresco Share (share.war) is a web application that runs on the Java Platform. In a development environment it is
usually deployed and run on top of Apache Tomcat. Share is built up of a main menu that leads to pages, which is
similar to most other web applications that you might come across. However, there is one special page type called
Dashboard that contains dashlets. A Dashboard page can be configured by the end-user, who can add, remove, and organize
the dashlets on the page.
Share pages and dashlets are implemented with something called web scripts, which is basically REST-based APIs. These APIs are called Surf web scripts when you are dealing with Alfresco Share. There is also repository web scripts that are used to extend the repository web application (alfresco.war) with REST-based APIs. Surf Web Scripts are referred to as Presentation Web Scripts and the repository web scripts as Data Web Scripts.
Share web scripts, pages, and dashlets are implemented with a user interface (UI) development framework called Surf. This framework was originally developed by Alfresco, then donated to the Spring Source foundation, and finally brought back into Alfresco products. It provides a way of breaking a HTML page into re-usable component parts. Surf is built on top of the Spring Web MVC technology, which in turn uses the Spring Framework.
Developers can also add completely new pages and dashlets to the Share UI when content should be viewed or handled in a specific way. Sometimes it is also required to modify existing pages. To customize the Share UI developers use so called Extension Points, which are supported ways of injecting new custom code that should alter the functionality of the Share web application.
The following picture gives an overview of the Alfresco Share application architecture, note that not all available extension points are illustrated in this picture:

Share gets the content that it should display in pages and dashlets by calling repository web scripts, which returns JSON or XML that can be incorporated into the presentation. The presentation is actually put together with two different kinds of JavaScript frameworks, Yahoo UI library (YUI) and Aikau, which is based on Dojo. An Aikau page is based on Surf but it makes page composition much easier than with pure Surf pages.
You can focus solely on Aikau if the only thing you are going to do is add new stuff to the Share UI. However, if you need to alter behavior of existing pages, then you might also need to get up to speed on the details of the Surf page model, as only the following has been converted to Aikau:
- Share Header Menu and Title (4.2)
- Live Search (5.0)
- Filtered Search Page (5.0)
- Search Management Page (5.0)
- Site Management Page (5.0)
- Analytics and Reporting Widgets (5.0)
- Document List prototype (5.0)
The following sections get into a bit more details around Surf pages and Aikau pages.
Server Side Framework (Surf)
The layout of a Share page is defined with the Surf development framework, which is a server side framework (Surf deep dive). This means that the involved files are processed on the server side (compared to Browser processing of JavaScript files). Surf is based on the Model View Controller (MVC) pattern where the controller(s) is mostly implemented in server side JavaScript (The Rhino JavaScript engine is included on the server side). The template is written in FreeMarker, and the model is a hash map that is set up in the controller(s) and available in the template.
Each page template defines one or more regions for things like header, footer, body, navigation, see the following picture:

To be able to reuse regions we can scope them to page, template, or global usage:

Each region is implemented as a reusable component. A component implementation is done with a Surf web script, which is the same thing as the REST-based request and response model, the predominant Web Service design model. The component web scripts will typically return HTML fragments that make up different parts of the page:

With all these different objects we might expect there to be some form of model that makes up the whole Surf UI development framework. It looks like this:

The model is referred to as the siteData and has more stuff than just pages and templates
(Surf Reference). You will however mostly be dealing with component,
page, and template-instance files, which are simple XML files:
/WEB-INF/classes/alfresco
/site-data
/chrome
/components
...
global.header.xml
/component-types
/configurations
/content-associations
/extensions
/page-associations
/pages
...
documentlibrary.xml
...
search.xml
...
task-details.xml
...
/page-types
/template-instances
1-column.xml
2-columns.xml
3-columns.xml
...
content-viewer.xml
...
search.xml
...
/template-types
/themes
The Site Data model defines the page in XML, like in the following
example for Search (alfresco/tomcat/webapps/share/WEB-INF/classes/alfresco/site-data/pages/search.xml):
<?xml version='1.0' encoding='UTF-8'?>
<page>
<title>Search</title>
<title-id>page.search.title</title-id>
<description>Search view</description>
<description-id>page.search.description</description-id>
<template-instance>search</template-instance>
<authentication>user</authentication>
<components>
<!-- Title -->
<component>
<region-id>title</region-id>
<url>/components/title/search-title</url>
</component>
<!-- Search -->
<component>
<region-id>search</region-id>
<url>/components/search/search</url>
</component>
</components>
</page>
Here we can see that some components have been defined inline
in the search page definition, instead of in the /components directory as separate files. The name of the page
definition file is implicitly setting the page id to search. A corresponding
template instance file is expected to be present in
the template-instances directory. In our case it will be a file called search.xml:
<?xml version='1.0' encoding='UTF-8'?>
<template-instance>
<template-type>org/alfresco/search</template-type>
</template-instance>
It will have a link to the physical template that contains the layout of the page. The template files are located under
a different directory called /templates, which is on the same level as the site-data directory:
/WEB-INF/classes/alfresco
/site-data
/templates
/org
/alfresco
1-column.ftl
2-columns.ftl
3-columns.ftl
...
content-viewer.ftl
...
search.ftl
...
The search.ftl template file looks like this with the regions etc:
<#include "include/alfresco-template.ftl" />
<@templateHeader />
<@templateBody>
<@markup id="alf-hd">
<div id="alf-hd">
<@region scope="global" id="share-header" chromeless="true"/>
</div>
</@>
<@markup id="bd">
<div id="bd">
<div class="yui-t1">
<div id="yui-main">
<@region id="search" scope="page" />
</div>
</div>
</div>
</@>
</@>
<@templateFooter>
<@markup id="alf-ft">
<div id="alf-ft">
<@region id="footer" scope="global" />
</div>
</@>
</@>
The search page reuses the global header and footer components and then defines a page specific region called search.
The web script to call for the search component is already defined in the page definition XML above (that is,
/components/search/search). The controller file for the search Web Script looks like this
(alfresco/tomcat/webapps/share/WEB-INF/classes/alfresco/site-webscripts/components/search/search.get.js):
/**
* Search component GET method
*/
function main()
{
// fetch the request params required by the search component template
var siteId = (page.url.templateArgs["site"] != null) ? page.url.templateArgs["site"] : "";
var siteTitle = null;
if (siteId.length != 0)
{
// Call the repository for the site profile
var json = remote.call("/api/sites/" + siteId);
...
This is server side JavaScript code that sets up a model with data for the template. The template looks like this
(alfresco/tomcat/webapps/share/WEB-INF/classes/alfresco/site-webscripts/components/search/search.get.html.ftl):
<@markup id="css" >
<#-- CSS Dependencies -->
<@link href="${url.context}/res/components/search/search.css" group="search"/>
</@>
<@markup id="js">
<#-- JavaScript Dependencies -->
<@script src="${url.context}/res/components/search/search-lib.js" group="search"/>
<@script src="${url.context}/res/components/search/search.js" group="search"/>
</@>
<@markup id="widgets">
<@createWidgets group="search"/>
</@>
<@markup id="html">
<@uniqueIdDiv>
<#assign el=args.htmlid>
<#assign searchconfig=config.scoped['Search']['search']>
<div id="${el}-body" class="search">
<#assign context=searchconfig.getChildValue('repository-search')!"context">
<#if searchQuery?length == 0 && context != "always">
<div class="search-sites">
...
The template is where we will find references to client side code/resources. The css and js sections above points
to the client side CSS and JS that should be part of the <head> section in the web page, and downloaded and executed
by the browser to create the user interface. So as we are starting to talk about the client side, let’s dig into it a
bit more in the next section.
Client Side Frameworks (Surf Pages and Aikau Pages)
To get an idea of the differences between the old school Surf pages, and the new Surf pages called Aikau, this example implements a simple page in both client side frameworks. The thing that might be a bit confusing to start with is that Aikau pages are also old school Surf pages under the hood. An Aikau page actually uses a predefined Surf page as a starting point. Start with an old school Hello World page and see how to add it to the Share UI.
Hello World Old School Surf Page
The following steps are needed to add a Surf Page:
- Add a Surf Page definition file (XML)
- Add a Template Instance file (XML)
- Add a physical Template file (FTL)
- Add a properties file (.properties) - Optional but good practice
- Add Web Script(s) that fetches content to display (if you have
pagescoped regions and use an existing template)
The full tutorial, and introduction to Surf Pages, can be found (here).
Next, have a look at how to implement the same Hello World page with Aikau.
Hello World Aikau Page
To implement the Hello World page in Aikau we have to go through the following steps:
- Add a Web Script descriptor (XML)
- Add a Web Script template (FTL)
- Add a Web Script controller (JS) with page layout/model
- Add Widget to display content
- Choose what Surf Page you want to use as a basis (dp, hdp, rdp etc)
For a full tutorial and introduction to Aikau Pages, see (Introduction to Aikau Pages).
Surf Pages introduction
Use this information for a brief introduction to Spring Surf Pages.
Let’s see how we can implement a Hello World page with the old school Surf Page framework.
The following steps are needed to add a Surf Page:
- Add a Surf Page definition file (
.xml) - Add a Template Instance file (
.xml) - Add a physical Template file (
.ftl) - Add a properties file (
.properties) - Optional but good practice - Add Web Script(s) that fetches content to display (if you have
pagescoped regions and use an existing template)
Let’s start out with the page definition file, create a file called helloworldhome.xml in the
alfresco/tomcat/shared/classes/alfresco/web-extension/site-data/pages directory. You will have to create the
site-data and pages directories. We are not using a build project to be able to focus solely on Surf.
Add the following XML to the file:
<?xml version='1.0' encoding='UTF-8'?>
<page>
<title>Hello World Home</title>
<title-id>page.helloworldhome.title</title-id>
<description>Hello World Home Description</description>
<description-id>page.helloworldhome.description</description-id>
<template-instance>helloworldhome-three-column</template-instance>
<authentication>none</authentication>
</page>
Here we are defining the title and description of the page both hard-coded in the definition, and as references to a
properties file with labels (i.e. the title-id and description-id elements). The page will not require any
authentication, which means we cannot fetch any content from the Alfresco Repository from it. It is also going to use
a three column template, or that is the idea, you can name the template instance whatever you want.
Now create the template instance file called helloworldhome-three-column.xml in the
alfresco/tomcat/shared/classes/alfresco/web-extension/site-data/template-instances directory.
You will have to create the template-instances directory:
<?xml version='1.0' encoding='UTF-8'?>
<template-instance>
<template-type>org/alfresco/demo/helloworldhome</template-type>
</template-instance>
This file just points to where the FreeMarker template for this page will be stored. So create the
alfresco/tomcat/shared/classes/alfresco/web-extension/templates/org/alfresco/demo directory path.
Then add the helloworldhome.ftl template file to it:
This is just a test page. Hello World!
Continue with the properties file for the page title and description. Create a file called helloworldhome.properties
in the alfresco/tomcat/shared/classes/alfresco/web-extension/messages directory.
You will have to create the messages directory:
page.helloworldhome.title=Hello World
page.helloworldhome.description=Hello World Home Description
This file just points to where the FreeMarker template for this page will be stored. We also need to tell
Alfresco Share about the new resource file, rename the custom-slingshot-application-context.xml.sample
to custom-slingshot-application-context.xml, it is located in the web-extension directory.
Then define the following bean:
<bean id="org.alfresco.demo.resources" class="org.springframework.extensions.surf.util.ResourceBundleBootstrapComponent">
<property name="resourceBundles">
<list>
<value>alfresco.web-extension.messages.helloworldhome</value>
</list>
</property>
</bean>
To test this page you will have to restart Alfresco. It can then be accessed via the http://localhost:8080/share/page/helloworldhome.
The page does not look very exciting:

So we are missing both the Share header and footer, which turns out to be global components that we can easily include.
We just need to change the template file a bit. Open up the helloworldhome.ftl file and change it so it looks like this:
<#include "/org/alfresco/include/alfresco-template.ftl" />
<@templateHeader></@>
<@templateBody>
<@markup id="alf-hd">
<div id="alf-hd">
<@region scope="global" id="share-header" chromeless="true"/>
</div>
</@>
<@markup id="bd">
<div id="bd">
<h1>This is just a test page. Hello World!</h1>
</div>
</@>
</@>
<@templateFooter>
<@markup id="alf-ft">
<div id="alf-ft">
<@region id="footer" scope="global" />
</div>
</@>
</@>
What we are doing here is first bringing in another FreeMarker file called alfresco-template.ftl that contains,
you guessed it, FreeMarker template macros. We then use these macros (elements starting with @) to set up the layout
of the page with header and footer. The header and footer content is fetched via the share-header and footer global
scope components (Web Scripts). To view the result of our change we need to restart the server again, after this we
should see the following:

So that looks a bit better. The next thing we want to do is to make the page a bit more dynamic, currently we have hard-coded the content for the page in the template. Let’s add a Web Script that will return the content to display. This will require us to update the template with an extra region as follows:
<#include "/org/alfresco/include/alfresco-template.ftl" />
<@templateHeader></@>
<@templateBody>
<@markup id="alf-hd">
<div id="alf-hd">
<@region scope="global" id="share-header" chromeless="true"/>
</div>
</@>
<@markup id="bd">
<div id="bd">
<@region id="body" scope="page" />
</div>
</@>
</@>
<@templateFooter>
<@markup id="alf-ft">
<div id="alf-ft">
<@region id="footer" scope="global" />
</div>
</@>
</@>
We have called the new region body and set page scope for it. This requires us to define a new component for this
region. This can be done either in the page XML, or as a separate file in the site-data/components directory, we will
do the latter. Create the components directory and add a file called page.body.helloworldhome.xml to it:
<?xml version='1.0' encoding='UTF-8'?>
<component>
<scope>page</scope>
<region-id>body</region-id>
<source-id>helloworldhome</source-id>
<url>/components/helloworld/body</url>
</component>
The component file names follow a naming convention: global | template | page>.<region-id>.[<template-instance-id | page-id>].xml
The URL for this component points to a Web Script that will return the Hello World message. Start implementing it by
creating a descriptor file called helloworld-body.get.desc.xml located in the
alfresco/tomcat/shared/classes/alfresco/web-extension/site-webscripts/org/alfresco/demo directory:
<webscript>
<shortname>helloworldbody</shortname>
<description>Returns the body content for the Hello World page.</description>
<url>/components/helloworld/body</url>
</webscript>
Note that the URL is the same as we set in the component definition. Now implement the controller for the Web Script,
create a file called helloworld-body.get.js in the same place as the descriptor:
model.body = "This is just a test page. Hello World! (Web Scripting)";
The controller just sets up one field in the model with the Hello World message. Now implement the template for the Web Script,
create a file called helloworld-body.get.html.ftl in the same place as the descriptor:
<h1>${body}</h1>
Restart the server. Then access the page again, you should see the Hello World message change to This is just a test page. Hello World! (Web Scripting).
To summarize a bit, the following is a picture of all the files that were involved in creating this Surf page the old school way:

What you could do now is extend the Hello World page with some more sophisticated presentation using the YUI library. If you do that you end up with the pattern for how most of the old school Share pages have been implemented.
Next we will have a look at how to implement the same Hello World page the new way with Aikau.
Aikau Pages introduction
Use this information for a brief overview of Aikau Pages.
Let’s see how we can implement a Hello World page with the new Aikau framework.
The following steps are needed to add an Aikau Page:
- Add a Web Script descriptor (XML)
- Add a Web Script template (FTL)
- Add a Web Script controller (JS) with page layout/model
- Add Widget to display content
- Choose what Surf Page you want to use as a basis (dp, hdp, rdp etc)
OK, this might be a bit confusing, starting with a web script and then selecting a Surf page? If you have read through the Share architecture page then you will remember that an Aikau page is based on a predefined Surf Page. So when you implement an Aikau page you are actually bypassing all the Site Data model stuff, and you go directly to the Web Script implementation that does the real job of fetching content and defining the presentation.
Start implementing the Aikau Page web script by creating a descriptor file called helloworld-aikau.get.desc.xml
located in the alfresco/tomcat/shared/classes/alfresco/web-extension/site-webscripts/org/alfresco/demo directory:
<webscript>
<shortname>Hello World</shortname>
<description>Hello World page definition</description>
<family>Share</family>
<url>/helloworld</url>
</webscript>
Now implement the controller for the Web Script, create a file called helloworld-aikau.get.js in the same place as the descriptor:
model.jsonModel = {
widgets: [
{
id: "SET_PAGE_TITLE",
name: "alfresco/header/SetTitle",
config: {
title: "Hello World"
}
},
{
id: "DEMO_SIMPLE_MSG",
name: "example/widgets/HelloWorldTextWidget"
}
]
};
The controller is where the main work is done when it comes to implementing the layout of the page. If you do not need
any custom widgets then it might even be the only major thing you need to implement to get the Aikau page up and running.
Now implement the template for the web script, create a file called helloworld-aikau.get.html.ftl in the same place
as the descriptor:
<@processJsonModel />
The template just kicks off the processJsonModel FreeMarker template macro, which will, as it says, process the JSON
model and assemble the page components.
Our page model contains an example widget that we need to implement. It is specified to be at the example/widgets
package path. Dojo is the JavaScript framework used behind the scenes, and we need to tell it about the new package path.
This can be done via a Spring Surf Module extension. Create a file called example-widgets.xml and put it in the
alfresco/tomcat/shared/classes/alfresco/web-extension/site-data/extensions directory:
<extension>
<modules>
<module>
<id>Example Aikau Widgets</id>
<version>1.0</version>
<auto-deploy>true</auto-deploy>
<configurations>
<config evaluator="string-compare" condition="WebFramework" replace="false">
<web-framework>
<dojo-pages>
<packages>
<package name="example" location="js/example"/>
</packages>
</dojo-pages>
</web-framework>
</config>
</configurations>
</module>
</modules>
</extension>
Now we can start implementing the Aikau Widget that should return the Hello World message. To do that we need to
implement a new Dojo JavaScript class called HelloWorldTextWidget. The widget is pure client side resource stuff so
we need to add the files involved into the exploded Share web app (this is just because we are not using a build project).
Create a file called HelloWorldTextWidget.js and put it in the alfresco/tomcat/webapps/share/js/example/widgets directory:
define(["dojo/_base/declare",
"dijit/_WidgetBase",
"alfresco/core/Core",
"dijit/_TemplatedMixin",
"dojo/text!./HelloWorldTextWidget.html"
],
function(declare, _Widget, Core, _Templated, template) {
return declare([_Widget, Core, _Templated], {
templateString: template,
i18nRequirements: [ {i18nFile: "./HelloWorldTextWidget.properties"} ],
cssRequirements: [{cssFile:"./HelloWorldTextWidget.css"}],
buildRendering: function example_widgets_HelloWorldTextWidget__buildRendering() {
this.helloWorldMsg = this.message('hello.world');
this.inherited(arguments);
}
});
});
This widget is based on an HTML template defined in a file called HelloWorldTextWidget.html, create this file in the
same place as the Widget class:
<div class="helloWorldMsgStyle">${helloWorldMsg}</div>
The widget also uses a property called hello.world that needs to be available in a resource file called
HelloWorldTextWidget.properties, create it in the same place as the Widget class:
hello.world=This is just a test page. Hello World! (Aikau)
Finally the widget template uses a CSS style called helloWorldMsgStyle that needs to be available in a resource file
called HelloWorldTextWidget.css, create it in the same place as the Widget class:
.helloWorldMsgStyle {
border: 1px #000000 solid;
padding: 1em;
width: 100px;
background-color:lightgrey;
}
Now restart Content Services and then access the page with the http://localhost:8080/share/page/hdp/ws/helloworld URL.
You should see the following page in Share:

The page we choose as a basis (that is, the Hybrid Dynamic Surf Page - hdp) provides both the header and the footer
for the Share web application. If you want to see the page stand-alone you can use the dp page as a basis.
So when we are working with Aikau pages we do not have to bother about the Site Data model and all the different kinds of XML files. We just create a web script where the controller will contain the complete layout of the page. And then the page content will go into an auto-generated region on the Surf page we select.
Surf Framework introduction
Surf lets you build user interfaces for web applications using server-side scripts and templates without Java coding, recompilation, or server restarts. Surf follows a content-driven approach, where scripts and templates are simple files on disk so that you can make changes to a live site in a text editor.
Surf is a Spring framework extension for building new Spring framework applications or plugging into existing Spring web MVC (Model, View, Controller) applications. Spring Web MVC provides separation between the application Model, View, and Controller (known as MVC). You can use Surf with other popular Spring Web MVC technologies including Tiles, Grails, and Web Flow.
Surf’s object model lets you define pages, templates, components, and themes using XML. The Spring application picks up new files and processes them through scripts and templates to produce the view, and writes scripts using server-side JavaScript and Groovy. Templates are written using FreeMarker. You can build both page-centric and content-centric websites using Surf, and it provides out-of-the-box support for rendering content delivered through content delivery services, such as CMIS, Atom, and RSS.
Note: The Groovy
invokedynamicindylibrary is included in Content Services. Depending on the JVM version, you can target close to Java performance for dynamic Groovy withinvokedynamicsupport activated.
Features:
- Scripts and templates: Everything in Surf consists of scripts, templates, or configuration. This means no server restarts or compilation.
- Reusability: Surf’s presentation objects, templates, and scripts emphasize reusability. Scoped regions and component bindings allow you to describe presentation with less code.
- Spring Web MVC: Surf plugs in as a view resolver for Spring Web MVC, enabling you to use Surf for all or part of a site’s view resolution. Surf renders views on top of annotated controllers and is plug-compatible with Spring Web Flow, Spring Security, Spring Roo, and Spring tag libraries.
- RESTful scripts and templates: All page elements and remote interfaces are delivered through a RESTful API. The full feature set of web scripts is available to Surf applications. Write new remote interfaces or new portlets with a script, a template, and a configuration file.
- Content management: A set of client libraries and out-of-the-box components streamline interoperability with CMIS content management systems, letting you easily access and present Enterprise content using Surf components and templates.
- Two-tier architecture: Surf works in a decoupled architecture where the presentation tier is separate from the content services tier.
- Production, development, and staging/preview: Configure Surf to work in a number of deployment scenarios including development, preview, or production environments.
- Development tools: Tools that plug into the SpringSource suite of development tools include Eclipse add-ons for SpringSource Tool Suite, as well as Spring Roo plug-ins to enable scaffolding and script-driven site generation.
APIs
To access and extend out-of-the-box services, the content application server exposes two flavors of API, each designed for a specific type of client.
The two main categories of API that are available to use when interacting with the Alfresco Repository is the remote and the embedded APIs.
Remote APIs
The main remote Application Programming Interface (API) is the Alfresco ReST API, which should be the first place you go to when you want to interact with the Alfresco Repository remotely. If portability is very important, than have a look at the CMIS ReST API, which is a standard implemented by many ECM vendors.
Embedded APIs
The embedded APIs have traditionally been used a lot to build customizations that run inside the same JVM as the Alfresco Repository. There are both a Public Java API and a Repository JavaScript API. Before using the embedded APIs a thorough investigation should be done to rule out the possibility of building the extension with a remote a remote API. It is not recommended to build embedded extensions unless it is absolutely necessary. They make it difficult during upgrades and can quite easily have unintended side effects on core repository functionality, such as file upload.