After creating the shards manually, an Alfresco Content Services administrator has to instruct Alfresco Content Services how to find the indexes. This can either be done manually by configuring the indexes, or by allowing Alfresco Content Services to discover shards dynamically. This section describes how to create and configure Solr sharding.
As shown in the diagram below, the trackers communicate with the repository. When the user initiates a query, it can either be executed by manually mapping the stores (explicit configuration), or by shard registry via dynamic sharding. Dynamic sharding determines what best shards are available to answer a query. The shard registry stores all the information about that particular index, for example the status of the index, transactions in index, and so on.

The query is sent to Solr and then to the request handler. The request handler determines if the query is local or distributed. In case of a distributed query, the query is sent to other parts of the index and then combined into an overall result.
The distributed query is done is two phases. Phase 1 involves query and an initial round of faceting, and Phase 2 involves pulling back information from each relevant document and facet refinement.
The following diagram shows the difference between manual and dynamic sharding. In this example, there are 4 shards (1, 2, 3, and 4) and 2 instances for each shard (A & E, B & F, C & G, and D & H). Instances A, B, C, D, and F are up-to-date, while the instances E and G are lagging behind and can’t be used. Shard instance H is silent and therefore, unavailable for querying.

In manual sharding, the user is only aware of the existence of the shards and its instances but knows nothing about the status of each shard and its instance(s). So, the query can be sent to any instance. In dynamic sharding, Alfresco Content Services will use instance A, B, C, D, or F for querying.

At query time, Solr is aware of all the available nodes and selects one node as the coordinator (one node from all the available green ones) and sends the request to it. Also, the shards (A, B, C, D or A, F, C, D) to be used for that request are selected dynamically. In this case, Solr selects F instead of B. So, if one node lags behind or stops responding, Solr stops using it.
Creating Solr shards manually
You can control the distribution of your index by creating, configuring, and registering shards manually.
Manual sharding overview
An index can be distributed over several Solr nodes by creating and configuring shards. This can be achieved in three steps. First, the Solr nodes (i.e. instances of Alfresco Content Services) must be started, second the shards must be created, and finally Alfresco Content Services must be configured to point to the Solr nodes.
-
Set the configuration properties that apply to all the cores in a Solr instance in the
<ALFRESCO_HOME>/alfresco-insight-engine/solrhome/conf/shared.propertiesfile.For shard registration, Alfresco Content Services needs to know the Solr port where the requests should be sent. This can be configured, along with an explicit host name.
solr.host=<hostname> solr.port=8983These properties will be used when registering all cores found under the
<SOLR_HOME>directory. For more information, see About shared.properties file.Once the basic configuration is complete then start the Solr nodes.
-
Setup and configure the Solr nodes.
Example: Creating shards
Let’s consider an example for creating 8 shards, 3 instances of each shard, and 6 Solr nodes. As shown below, each node will get 4 different shards.
| Shard 0 | Shard 1 | Shard 2 | Shard 3 | Shard 4 | Shard 5 | Shard 6 | Shard 7 | |
|---|---|---|---|---|---|---|---|---|
| Node 1 | x | x | x | x | ||||
| Node 2 | x | x | x | x | ||||
| Node 3 | x | x | x | x | ||||
| Node 4 | x | x | x | x | ||||
| Node 5 | x | x | x | x | ||||
| Node 6 | x | x | x | x |
To achieve this sharding configuration, follow the steps below for each Solr node N:
-
Delete any existing
alfrescoandarchivecores using the following commands.https://<hostnameN>:8983/solr/admin/cores?action=removeCore&storeRef=workspace://SpacesStore&coreName=alfresco https://<hostnameN>:8983/solr/admin/cores?action=removeCore&storeRef=workspace://SpacesStore&coreName=archive -
Recreate the sharded cores to set up index tracking.
Call the following URLs:
http://<hostnameN>:<portN>/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=8&nodeInstance=N&replicationFactor=3&numNodes=6&template=rerank http://<hostnameN>:<portN>/solr/admin/cores?action=newCore&storeRef=archive://SpacesStore&numShards=8&nodeInstance=N&replicationFactor=3&numNodes=6&template=rerank -
For each core (alfresco and archive), the properties can be set at the creation time or updated later.
https://<hostnameN>:<portN>/solr/admin/cores?action=updateCore&storeRef=system://system&property.data.dir.store=<SOME_VALUE>
You should now have six nodes with four cores, each actively tracking the repository. The following URL options are available for use:
| URL option | Description |
|---|---|
| numShards | Specifies the number of logical shards, for example 8. |
| storeRef | Specifies reference to a node store, for example workspace://SpacesStore |
| template | Defines the base configuration for a new Solr core with some configuration properties set using the URL as shown in Step 1(b).For more information, see Core templates, for example template=rerank. |
| replicationFactor | Specifies the number of copies of each document (or, the number of physical instances to be created for each logical shard). A replicationFactor of 3 means that there will be 3 instances for each logical shard, for example 3. |
| nodeInstance | Specifies the Solr node instance being configured, for example 6. |
| numNodes | Returns the total number of Solr nodes for example 6. |
| coreName | Specifies the name of the Solr core, for example alfresco. |
| property.<> | Specifies the property and its value, for example property.data.dir.store=... |
-
Configure Alfresco Content Services by setting the Solr subsystem properties.
Set the three Solr subsystem properties for both the
alfrescoandarchivecores in the alfresco-global.properties file. For example, you can set the properties as shown below:solr6.store.mappings.value.solrMappingAlfresco.nodeString=<hostname1>:<port1>/<url1>,<hostname2>:<port2>/<url2> solr6.store.mappings.value.solrMappingAlfresco.numShards=8 solr6.store.mappings.value.solrMappingAlfresco.replicationFactor=3 solr6.store.mappings.value.solrMappingArchive.nodeString=<hostname1>:<port1>/<url1>,<hostname2>:<port2>/<url2> solr6.store.mappings.value.solrMappingArchive.numShards=8 solr6.store.mappings.value.solrMappingArchive.replicationFactor=3
In the above examples, nodeString is a list of URLs where the alfresco core can be accessed.
For a two node system with Solr node 1: http://<hostname1>:<port1>/solr/#/alfresco, and Solr node 2: http://<hostname2>:<port2>/solr/#/alfresco, then:
solr6.store.mappings.value.solrMappingAlfresco.nodeString=<hostname1>:<port1>/solr/#/alfresco,<hostname2>:<port2>/solr/#/alfresco
Similarly, set nodeString for the archive core.
Note: These properties can also be configured via a JMX client or using the subsystem properties to reference the composite beans. Note: If the host, port, or URL is missing, the subsystem default values (the ones set for a single index) will be used. Ensure the hosts are in the correct order. This is because Solr assumes that the shards are located on node 1, etc. as defined in the above list when generating queries. At query time, a Solr core is selected at random to do the distribution of all shards, again, selected at random.
Core templates
Core templates are used to define the base configuration for a new Solr core with some configuration properties.
Search and Insight Engine provides two Solr core templates out of the box. These templates live in the following folders:
<SOLR_HOME>/templates/rerank
<SOLR_HOME>/templates/noRerank
- The
reranktemplate includes tuning on rating scores in order to obtain finer relevance and precision. - The
noReranktemplate provides the same configuration but without tuning.
If you don’t specify additional options when creating the cores, the rerank template is taken as the base configuration for both the alfresco and archive cores. For example, this is what happens when you use the “-Dcreate.alfresco.defaults=alfresco,archive” option. In this example, the rerank folder is copied to your deployment directories (as shown below), and noRerank is never used:
<SOLR_HOME>/templates/rerank >> <SOLR_HOME>/alfresco
<SOLR_HOME>/templates/rerank >> <SOLR_HOME>/archive
So, if you’re creating your Solr cores from scratch, you only need to modify the following file:
<SOLR_HOME>/templates/rerank/conf/solrcore.properties
If you’re using a persistent storage configuration, with both alfresco and archive cores, having indexes, you need to change the configuration for the properties file for each core:
<SOLR_HOME>/archive/conf/solrcore.properties
<SOLR_HOME>/alfresco/conf/solrcore.properties
The core templates are specified in the URL used for creating shards, as shown below:
http://<hostN>:<portN>/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=8&nodeInstance=N&replicationFactor=3&numNodes=6&**template=<template>**
The <SOLR_HOME>/templates directory contains the following structure:
| Templates | Description |
|---|---|
| rerank | This template is an enhanced core configuration for Alfresco Content Services. To use rerank, you need to reindex using this template when creating a new core. It has more appropriate settings for sharding and supports indexes containing approximately 50-80M documents per shard. |
| noRerank | This template matches how the alfresco and archive cores were defined in Alfresco One 5.0. In addition, it supports auto-phrasing and query re-ranking. |
The core templates include schema.xml and solrconfig.xml. The main purpose is to create multiple cores on multiple machines with the same configuration.
Note: The
apsandrerankWithQueryLogtemplates have been removed from the default distribution of Search and Insight Engine from version 1.4 onwards.
Comparison between the rerank and noRerank templates
| No. | Rerank template | noRerank template |
|---|---|---|
| 1 | The rerank template causes less duplication of the index, and therefore the index is more compact. | The noRerank template causes more duplication of the index, and therefore the index is large. |
| 2 | In the rerank template, stop words are included and indexed as common grams. By default, majority of the 100 most frequently used words in English language text are now treated as stop words. For more information, see <SOLR_HOME>/templates/rerank/conf/lang/stopwords_en.txt. |
In the noRerank template, stop words are removed from the words that are tokenised in the English language. For more information, see <SOLR_HOME>/templates/norerank/conf/lang/stopwords_en.txt. |
| 3 | The rerank template supports real rerank with automatic phrasing (or auto-phrasing). Queries are run in two stages: 1. Stage one treats phrases as conjunctions and ignores expensive positional information. 2. Stage two reranks the top queries using a more expensive phrase. When a user provides individual search terms in a query, the automatic phrasing feature groups those individual terms into a search phrase and returns the query results for the phrase. | The noRerank core performs auto-phrasing without re-ranking but the auto-phrase is added to the query. |
About shared.properties file
The <ALFRESCO_HOME>/alfresco-insight-engine/solrhome/conf/shared.properties file is used to set configuration that applies to all the cores in a Solr instance.
Most of these settings need to be replicated across all the Solr instances that are a part of the sharded index. However, there are some properties related to dynamic shard registration, such as host and port, which can be set for each machine.
These Solr instance specific settings can be omitted but you may have to define the correct host that the repository will use to communicate to Solr, for example, using an internal IP address in a cloud environment. By default, the host is detected by Java, the port will default to 8080, and the tomcat port is either determined by JMX or that explicitly defined in the shared.properties file.
The shared.properties file defines the:
- properties that are treated as identifiers
- properties that are used to generate suggestions
- data types that support cross locale/word splitting/token pattern
- properties that support cross locale/word splitting/token pattern
solr.hostpropertysolr.portproperty
Properties defined in the shared.properties file
You can define which properties are treated as identifiers, regardless of how they are defined in the model. These properties must not be tokenised. If this list is changed, a reindex is required. You can also reindex by query. For more information, see Reindex documents by query.
If you rename the shared.properties.sample file to shared.properties, it will use the same set of identifier properties that are used in Alfresco One 5.0.
# Properties treated as identifiers when indexed
alfresco.identifier.property.0={http://www.alfresco.org/model/content/1.0}creator
alfresco.identifier.property.1={http://www.alfresco.org/model/content/1.0}modifier
alfresco.identifier.property.2={http://www.alfresco.org/model/content/1.0}userName
alfresco.identifier.property.3={http://www.alfresco.org/model/content/1.0}authorityName
alfresco.identifier.property.4={http://www.alfresco.org/model/content/1.0}lockOwner
You can define which properties are used for suggestion.
# Suggestable Properties
#alfresco.suggestable.property.0={http://www.alfresco.org/model/content/1.0}name
#alfresco.suggestable.property.1={http://www.alfresco.org/model/content/1.0}title
#alfresco.suggestable.property.2={http://www.alfresco.org/model/content/1.0}description
#alfresco.suggestable.property.3={http://www.alfresco.org/model/content/1.0}content
Suggestion can also be configured for the search subsystem and for any SOLR core using properties. If the shared.properties file is missing in Alfresco Content Services 6.2, suggestion will be configured as it is in Alfresco One 5.0.
You can define which properties are used for tokenisation with the Solr word delimiter factory.
# Data types that support cross locale/word splitting/token patterns if tokenised
alfresco.cross.locale.property.0={http://www.alfresco.org/model/content/1.0}name
alfresco.cross.locale.property.1={http://www.alfresco.org/model/content/1.0}lockOwner
You can define which property types are used for tokenisation with the Solr word delimiter factory.
# Data types that support cross locale/word splitting/token patterns if tokenised
# alfresco.cross.locale.datatype.0={http://www.alfresco.org/model/dictionary/1.0}text
# alfresco.cross.locale.datatype.1={http://www.alfresco.org/model/dictionary/1.0}content
# alfresco.cross.locale.datatype.2={http://www.alfresco.org/model/dictionary/1.0}mltext
Support for cross-language search
The cross core configuration options to use specific locales for cross-locale searches are set in the shared.properties file. Cross language search uses the appropriate stemmed tokens for all locales.
For backward compatibility, this file is absent in Alfresco Content Services 6.2 to provide options equivalent to Alfresco One 5.0.
To configure cross-language search, follow the steps below:
- Open the
<ALFRESCO_HOME>/alfresco-insight-engine/solrhome/conf/shared.properties.samplefile. -
Set the following properties:
alfresco.cross.locale.property.0={http://www.alfresco.org/model/content/1.0}name alfresco.cross.locale.property.1=...This sets the properties that should be dual tokenised.
The cross-language search in Alfresco One 5.0 is now only used to provide support to split tokens (based on case and numbers) to generate
in wordtokens. Thein wordtokenisation is mainly used for name. For example, findRedDog12byRed,Dog, or12,Dog12, and so on. This property must be indexed and tokenised. -
To specify the same behaviour based on the data type, set the following properties:
alfresco.cross.locale.datatype.0={http://www.alfresco.org/model/dictionary/1.0}text alfresco.cross.locale.datatype.1=...
Query time expansion of locales
Query time expansion of locales can be defined in the solrconfig.xml file as part of the query language definition.
| Locale parameter | Description |
|---|---|
| autoDetectQueryLocale | If true, this uses the query typed in by the user to detect the locale. |
| autoDetectQueryLocales | This specifies a set of locales. One of these may be used in executing the query if autoDetectQueryLocale=true. |
| fixedQueryLocales | This specifies a fixed set of locales always used by the query. |
What locales are used?
- The locale for the current session is always used.
- If the
autoDetectQueryLocaleparameter is used, then the best match fromautoDetectQueryLocalesis used. If no parameter is set, then all the possible locales are used. - All
fixedQueryLocalesare used.
Here are some example entries in the solrconfig.xml file:
<queryParser name="afts" class="org.alfresco.solr.query.AlfrescoFTSQParserPlugin">
<str name="rerankPhase">QUERY_PHASE</str>
<str name="autoDetectQueryLocale ">true</str>
<str name="autoDetectQueryLocales ">en,fr,de</str>
</queryParser>
<queryParser name="afts" class="org.alfresco.solr.query.AlfrescoFTSQParserPlugin">
<str name="rerankPhase">QUERY_PHASE</str>
<str name="fixedQueryLocales">en,fr,de</str>
</queryParser>
These are query time options and do not require a reindex. Currently, these values cannot be set in the solrcore.properties file.
Enabling path queries
The property alfresco.cascade.tracker.enabled provides Index fields that are required for path-based queries when set to true (the default is true). Disabling support for path queries (i.e. setting this to false) can speed up indexing in sharded systems.
Updating this property from the default setting will result in path-based fields not being populated. Consequently it should not be changed after the initial startup of the server.
Note: If
alfresco.cascade.tracker.enabledis set to false and Solr is restarted, cascaded updates are disabled.
When you disable cascade tracking and do not index fields that are updated on cascaded updates
This is the default setting when cascade tracking is disabled and as a result many search queries will not work, even for users with an environment where parent entries are not updated (e.g when a parent node has been renamed), such as SITE:swsdp.
This approach ensures search queries affected by disabling cascade tracking will not work, rather than risking inconsistent query results.
Review how the following services are affected:
- CMIS
IN_TREE,PATH,PARENT,ANCESTORqueries will not work.
- Search API
- Faceted Search (Facet Fields, Pivot Facet, Facet Range), PATH, NPATH, Secondary Association, Cascade Updates, Search with Sort queries will not work. *SQL API
- There are at least 70 less fields found in the Solr schema.
- SITE, PATH: fields are not indexed and SQL queries based on these fields will return null values.
- Queries will not be successful with these fields being used in predicates, for example queries with
<select * from alfresco where Site = ‘swsdp’>.
- Share
- Category Manager
http://localhost:8081/share/page/console/admin-console/category-managercan’t be used. - TAGs can’t be created or browsed.
- Your site can be defined as a Facet for Search Results (via Search manager) but it will not work.
- Searching within a site (or within a folder) returns a list of content within the site. This will not work, for example using
SITE:swsdpsyntax or via node browser using PATH queries. -
Node browser default PATH query doesn’t list system and category roots and PATH queries. If
alfresco.cascade.tracker.enabledis set to false and Solr is restarted cascaded updates will be disabled. To avoid inconsistencies in the results, by default the fields that are updated on cascade updates are not indexed.When parent paths have been updated or renamed, path queries are affected because the correct parent paths are available in the database but the Solr indexes for any children are not updated. The result of this can be inconsistent results for path queries and queries where parent/path are used.
These types of results will affect users when their environment allows for cascaded changes. The results of a search query that use the database and search/SQL, including the index, may not always match, if the parent path is updated (only in case of renaming a parent).
- Category Manager
Dynamic shard registration
In dynamic shard registration, shards register as a part of the tracking process to form indexes, thereby eliminating the need to follow the manual shard distribution pattern over Solr nodes.
Unlike manual sharding, dynamic sharding does not require shards and instances to be distributed correctly over a known set of hosts. Query is resilient, with a configurable delay to instances coming and going. For manual sharding, all instances must be available on the expected host at the expected URL. While dynamic shard registration allows different numbers of instances for any shard, manual sharding does not.
To enable dynamic sharding, set the following property in the alfresco-global.properties file:
solr.useDynamicShardRegistration=true
The following properties govern which instances are chosen for a query:
search.solrShardRegistry.purgeOnInit=true
search.solrShardRegistry.shardInstanceTimeoutInSeconds=300
search.solrShardRegistry.maxAllowedReplicaTxCountDifference=1000
| Property | Description |
|---|---|
| search.solrShardRegistry.purgeOnInit | If true, this property removes persisted shard state from the database when the subsystem starts for example, true |
| search.solrShardRegistry.shardInstanceTimeoutInSeconds | Specifies that if a shard has not made a tracking request within this time, it will not be used for query. Note: When tracking large change sets or rebuilding your indexes, increase the shard timeout. For example, change the value of this property to 3200 or 7200 seconds |
| search.solrShardRegistry.maxAllowedReplicaTxCountDifference | Specifies that if any shard is more than this number of transactions behind the leading instance, it will not be used, for example 1000 transactions |
| search.solrShardRegistry.dbidRangeRefreshTimeoutInSeconds | This property controls the frequency of synchronisation of the shard information between multiple ACS instances for DB_ID_RANGE sharding, for example 30. Note: This property is only used when you are using DB_ID_RANGE sharding with multiple ACS instances. |
If there is more than one index for a store, the most up to date index (the one that has indexed most transactions) will be used. For each shard, an instance is chosen at random from all the shards that are actively tracking and within 1000 transactions of the lead instance.
Shards are considered to be part of the same index if they:
- track the same store
- use the same template (and therefore, Solr schema)
- have the same number of shards
- use the same partitioning method with the same configuration, if any is required
- have the same setting to transform or ignore content
In dynamic sharding, shards can be created using the same API as manual sharding or you can list the required shards as a comma-separated list of shardIds.
http://localhost:8080/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=10&
numNodes=1&nodeInstance=1&property.data.dir.root=<SOLR_HOME>/solrhome/workspace-SpacesStore&shardIds=0,1,2,3,4
The status of all the available indexes, shards, and instances can be found using a JMX client. For more information, see Indexing JMX client.
Dynamic sharding will currently use partial indexes to answer queries. For example, there are two shards: Shard1 and Shard2. If there are no instances for Shard2, queries will only use Shard1.
Installing and configuring Solr shards
Follow these steps to set up sharding of a non-sharded index or change the number of instances of an already sharded index.
Note: Do not use SSL with sharding.
-
Create machines to host Solr shards.
-
These machines are basically application servers that host the Solr webapp. If you install multiple Solr webapps on the same machine, each Solr instance must have a different configuration. In the
solr.xmlfile, edit the following parameters so that all Solr instances point to different root directories for each node:- solr/home
- solr/model/dir
Note: All the Solr instances hosting shards on a given host must have separate model and index locations.
-
-
Install and start Alfresco Content Services.
-
Delete the existing Solr indexes from the installation.
Delete the alfresco and archive cores using the following commands:
https://localhost:8443/solr4/admin/cores?action=removeCore&storeRef=workspace://SpacesStore&coreName=alfresco https://localhost:8443/solr4/admin/cores?action=removeCore&storeRef=workspace://SpacesStore&coreName=archive -
Add any custom core templates. For more information, see Core templates.
-
Configure the
/conf/shared.properties file. For more information, see [About shared.properties file](#About-shared.properties-file). -
Start the Solr server.
-
Create your new index shards and instances by configuring the properties on the URL.

http://localhost:8080/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore& numShards=10&numNodes=1&nodeInstance=1&template=rerank&property.data.dir.root=<>This URL configures a sharded cluster that contains 10 shards, 1 node, and 1 instance of each shard. The following options must be used in the URL:
numShardsspecifies the number of logical shards.numNodesspecifies the total number of Solr nodes.nodeInstanceis the actual Solr instance corresponding to thathost:port.templatedefines the basic configuration for a new Solr core with some configuration properties. For more information, see Core templates.storeRefspecifies reference to a node store. Here’s an example to show how to set a non-SSL port manually when creating a shard.
Example: If you want a sharded Solr installation with a different Tomcat port (8090), set the
property.alfresco.portproperty on the URL used to create the shard. Theproperty.alfresco.portproperty specifies the port used to communicate with the repository (or repositories through a load balancer). This property can also be set if communicating through a different host or load balancer. In this example, we will setproperty.alfresco.port=8090, as shown below:http://localhost:8080/solr/admin/cores?action=newCore&storeRef=workspace://SpacesStore& numShards=10&numNodes=1&nodeInstance=1&template=rerank&property.data.dir.root=<>&shardIds=0,1,2,3,4 &property.alfresco.port=8090 -
The Solr cores will register and start tracking the indexes.
If there are two indexes for the same store, the old index will be used until both the indexes are at the same state. Thereafter, both the indexes will be used.
-
Set the following properties in the
alfresco-global.propertiesfile.solr.secureComms=none solr.useDynamicShardRegistration=true -
Restart Alfresco Content Services.
-
You can turn off any old indexes from tracking. To do so, wait for the instances to time out which lets the new index be up-to-date. Alternatively, navigate to the JMX sharding operations and clear out all the registered shards, and start again.
You have a new live index.
High availability configuration
Sharding a Solr index is a highly scalable approach for improving the throughput and overall performance of large repositories. It provides high availability in case a shard/node fails.
Here are a few examples of a high availability configuration in a sharded Solr setup.
Example 1
In this example, you will setup a sharded cluster that contains:
- 3 hosts/machines
- 3 shards
- 2 copies
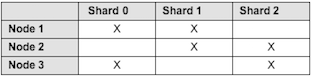
These are the steps to follow:
- Create machines to host Solr shards.
- Install and start Alfresco Content Services.
- Delete the Alfresco and archive cores.
- Configure the
/conf/shared.properties file. - Start the Solr server.
-
Create your new index shards and instances by configuring the properties on the URL.
http://localhost:8090/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=3&nodeInstance=1 &template=rerank&property.data.dir.root=<>&shardIds=0,1&property.alfresco.port=8080http://localhost:8070/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=3&nodeInstance=2 &template=rerank&property.data.dir.root=<>&shardIds=1,2&property.alfresco.port=8080http://localhost:8070/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=3&numNodes=3&nodeInstance=3 &template=rerank&property.data.dir.root=<>&shardIds=0,2&property.alfresco.port=8080 -
Set the following properties in the alfresco-global.properties file.
solr.secureComms=none solr.useDynamicShardRegistration=true - Restart Alfresco Content Services.
Example 2
Another example to setup a sharded cluster that contains:
- 5 hosts/machines
- 5 shards
- 3 copies
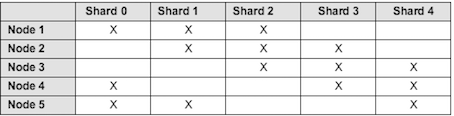
These are the steps to follow:
- Create machines to host Solr shards.
- Install and start Alfresco Content Services.
- Delete the Alfresco and archive cores.
- Configure the
<SOLR_HOME>/conf/shared.propertiesfile. - Start the Solr server.
-
Create your new index shards and instances by configuring the properties on the URL.
http://localhost:8090/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=5&numNodes=5&nodeInstance=1 &template=rerank&property.data.dir.root=<>&shardIds=0,1,2&property.alfresco.port=8080http://localhost:8070/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=5&numNodes=5&nodeInstance=2 &template=rerank&property.data.dir.root=<>&shardIds=1,2,3&property.alfresco.port=8080http://localhost:8070/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=5&numNodes=5&nodeInstance=3 &template=rerank&property.data.dir.root=<>&shardIds=2,3,4&property.alfresco.port=8080http://localhost:8070/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=5&numNodes=5&nodeInstance=4 &template=rerank&property.data.dir.root=<>&shardIds=0,3,4&property.alfresco.port=8080http://localhost:8070/solr4/admin/cores?action=newCore&storeRef=workspace://SpacesStore&numShards=5&numNodes=5&nodeInstance=5 &template=rerank&property.data.dir.root=<>&shardIds=0,1,4&property.alfresco.port=8080 -
Set the following properties in the
alfresco-global.propertiesfile.solr.secureComms=none solr.useDynamicShardRegistration=true - Restart Alfresco Content Services.
For more information, see Solr sharding.
Configuring sharding with the Admin Console
Search and Insight Engine supports sharded indexes with SSL. Use the Search Server Sharding page to set up and configure a Solr 6 sharded search index.
Prerequisites for viewing the Search Server Sharding page:
-
Check you have installed Alfresco Content Services 6.2 or above and have a valid license.
-
Support for shard groups requires a clustered license. Make sure that you enable clustering on your Alfresco Content Services license. For more information, see Install and configure Content Services nodes and Uploading a new license.
- Open the Admin Console. For more information, see Launch Admin Console.
-
In Repository Services, click Search Server Sharding.
You see the Search Server Sharding page. It displays information about dynamic shard index registration, shard groups, and shard instances.
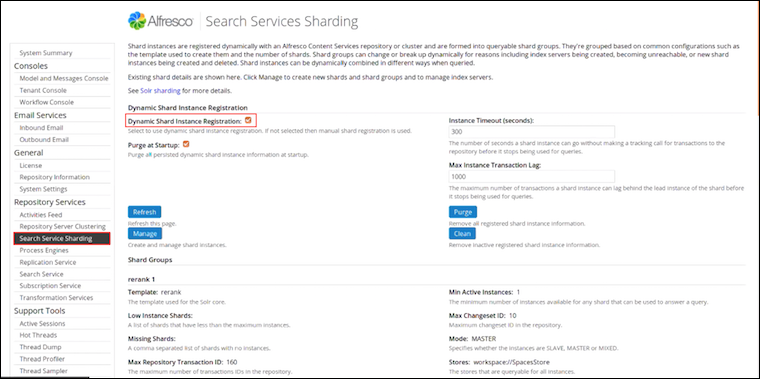
-
Under Dynamic Shard Instance Registration, select Dynamic Shard Instance Registration and set the other shard instance properties.
Shard registration property Description Dynamic Shard Instance Registration Enabled Select this property to enable dynamic shard instance registration. If disabled, manual shard registration is used, for example Yes.Purge at Startup This property purges all persisted dynamic shard instance information at startup, for example No.Instance Timeout (seconds) This specifies the number of seconds a shard instance can go without making a tracking call for transactions to the repository before it stops being used for queries. Note: When tracking large change sets or rebuilding your indexes, increase the shard timeout. For example, change the value of this property to 3200 or 7200 seconds. Max Instance Transaction Lag This specifies the maximum number of transactions an instance can lag behind the lead instance of the shard before it stops being used for queries, for example 1000. - Click Refresh to refresh this page.
- Click Purge to remove all registered shard instance information and start from clean.
- Click Clean to remove inactive registered shard instance information.
-
Click Manage to create and manage shard instances. You see the Index Server Shard Management window. Use this window to create individual shards or shard groups.
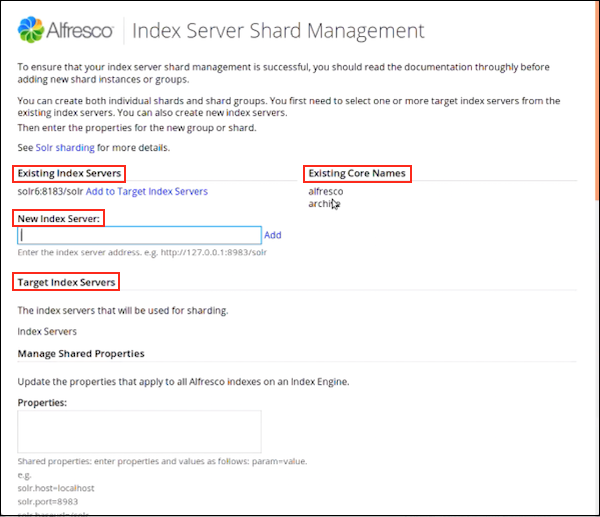
- Use Existing Index Servers to view a list of existing index servers and to create new index servers. To add a new index server, specify the server address in New Index Server and click Add. You can view the newly created index server under Target Index Servers. Click Add to Target Index Servers next to the server you want to add to the list of target index servers. Target Index Servers displays a list of index servers where you want to make the new shards.
- Under Existing Core Names, you can view a list of the core names already in use.
- Under Target Index Servers, you can view a list of index servers that will be used for sharding. To remove an index server from the list of servers that will be used for sharding, click Remove.
-
Next, you need to create a core for the shard. There are two ways to do this. You can either:
- use the Manage Default Indexes and Manage Shared Properties sections to create default indexes - see Step 7 (e) and 7 (f); or
- use the New Shard Group and New Shard Instance sections to create a shard group and instance - see Step 7 (g) and 7 (i).
-
Use Manage Default Indexes to create default indexes on the servers listed in Target Index Servers.
The Manage Default Indexes section:
- appears only when you add a new index server.
- creates a core for a given shard, and therefore, can be used as an alternative to creating shards using the New Shard Group section (Step 7f).
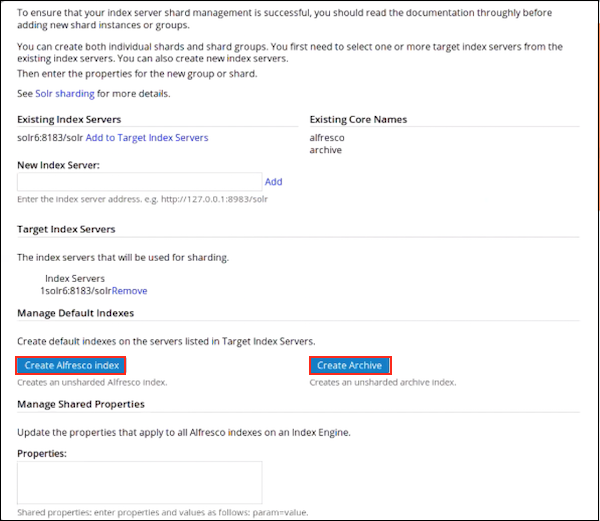
Important: The cores are visible in the Solr Admin web application only after you create them using the Index Server Sharding page.
- Click Create Alfresco Index to create an unsharded Alfresco index.
- Click Create Archive to create an unsharded archive index.
Use the Report section at the end of this page to view the detailed core creation message.
Check the Solr Admin UI to ensure that both the indexes are correctly listed.

-
Use Manage Shared Properties to update the properties that apply to all Alfresco indexes on an Index Engine.
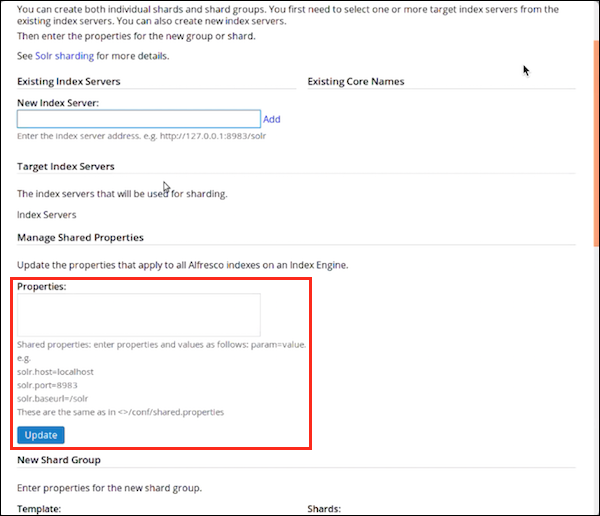
These properties are the same as in alfresco-insight-engine-distribution-2.0.x.zip/solrhome/conf/shared.properties. For example:
solr.host=localhost solr.port=8983 solr.baseurl=/solr -
Alternatively, to create a shard group, set the following properties under New Shard Group:
Shard group property Description Template This specifies the template used for the shard group, for example rerank Store This specifies the stores that are queryable for all shards, for example workspace://SpacesStoreCore This specifies the name of the Solr core. Properties This specifies the properties to set on the Solr instances. These are the same properties that are set in the solrcore.properties file, for example solr.suggester.enabledalfresco.secureComms=https,alfresco.port.ssl=8443,alfresco.commitInterval=20000, andalfresco.newSearcherInterval=30000.Shards This specifies the total number of shards, for example 1. Instances This specifies the total number of instances, for example 1. 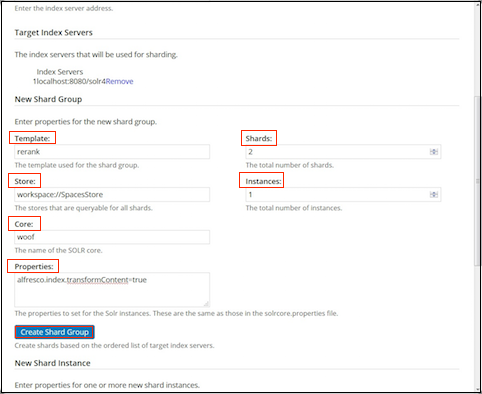
-
Click Create Shards Group to create new shards based on the ordered list of target index servers.
-
To create a single shard instance, set the following properties under New Shard Instance:
Shard property Description Index Server URL This specifies the URL to a single index server, for example localhost:8080/solNodes This specifies the total number of Solr nodes that have been created, for example 1. Target Index Server This specifies, out of all the solr nodes above, the number given to the target index server node for this new shard, for example 1. Shards This specifies the specific shards to create, on the node given above. You can also specify a comma-separated list of shards. See Solr sharding to view examples of creating shards when calling the REST URLs directly.
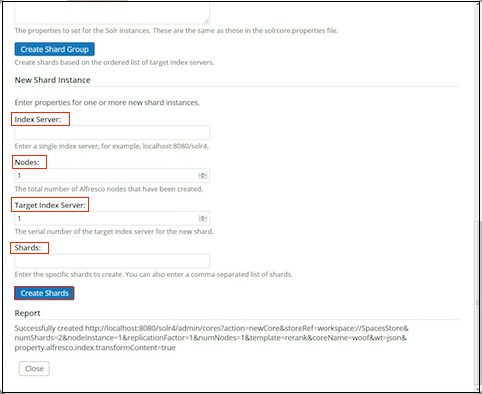
-
Click Create Shards to create the new shard based on the specified instance properties.
-
Use Report to get detailed information on shard creation and execution.
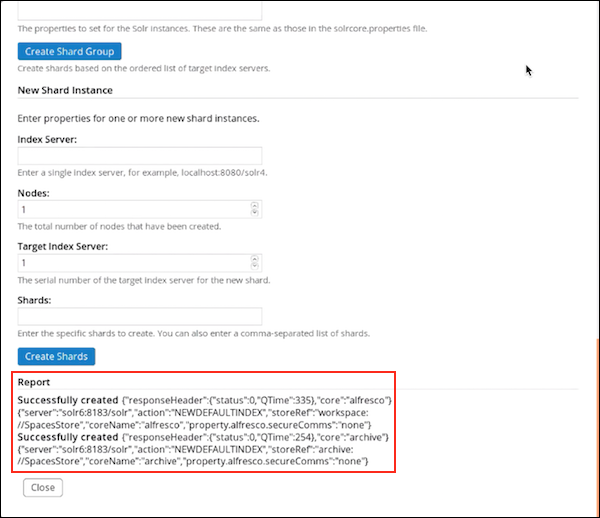
-
Click Close to close the Index Server Shard Management window.
You have successfully created an
alfrescocore and anarchivecore. To verify, in a browser, navigate to the Solr URL,https://localhost:8983/solr"https://localhost:8443/solr4. In the Solr Admin UI, select the core selector drop-down list and verify that both thealfrescoandarchivecores are present in the list.Validate that you can execute queries from the search public API to the archive core.
curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' --header 'Authorization: Basic YWRtaW46YWRtaW4=' -d '{ "query": { "query": "foo" }, "scope": { "stores": ["archive://SpacesStore"] } }' 'http://localhost:8080/alfresco/api/-default-/public/search/versions/1/search' -
Under Shard Groups, you can view information about all the shards in the group.
Property Description Template This specifies the template used for the Solr core, for example rerank Low Instance Shards This specifies a list of shards that have less than the maximum number of instances. Missing Shards This specifies a comma-separated list of shards with no instances, for example 100.Max Repository Transaction ID This specifies the maximum number of transaction IDs in the repository, for example 14,637.Max Live Instances This specifies the maximum number of instances available for any shard that can be used to answer a query, for example 1.Remaining Transactions This specifies the maximum number of transactions remaining for all the lead instances of all the active shards, for example 2.Number of Shards This specifies the total number of shards, for example 4.Min Active Instances This specifies the minimum number of instances available for any shard that can be used to answer a query, for example 1.Max Changeset ID This specifies the highest change set id in the repository, for example 104Mode This specifies whether the instances are SLAVE,MASTER, orMIXED. Note: TheSLAVEandMIXEDinstances are not supported for a sharded installation, for example master.Stores This specifies the stores that are queryable for all instances, for example workspace://SpacesStore.Has Content This property is enabled if content is included for all instances, for example EnabledShard Method This specifies the method used to define shards. The default shard method is DB_ID. You can specify your own shard method in Index Server Shard Management screen > New Shard Group > Properties. For example,shard.method=ACL_ID. You can also set this property in thealfresco-insight-engine-distribution-2.0.x.zip/solrhome/templates/rerank/conf/solrcore.propertiesfile.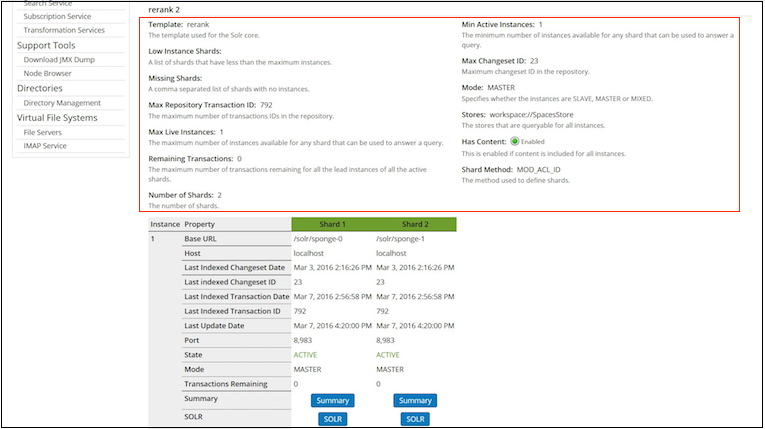
-
Use the instance property table to view detailed entity information for all the shards. This is the same information that is displayed in the JMX console, for example,
Base URL,Host,Last Indexed Changeset Date, and more.For more information, see Indexing JMX client.
-
Click Summary to go to the http://localhost:8983/solr/admin/cores?action=SUMMARY page on Solr for the specific core.
For more information, see Unindexed Solr Transactions.

-
Click SOLR to go to the Solr Admin screen for the specific core.
For more information, see Connecting to the SSL-protected Solr web application
-
-
The Shard Group Report section displays information about the shard groups and instances. A tabular view of this information is displayed in the shard table in Step 9. This information is read-only.
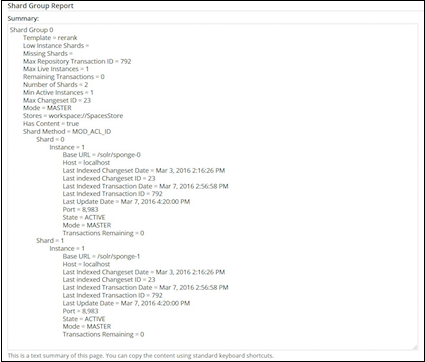
-
Click Save to apply the changes you have made to the index server shards.
If you do not want to save the changes, click Cancel.
Note: Alfresco recommends that you do not use the Solr Admin Console > Core Admin > Unload functionality to unload indexes (either whole indexes or shards that are part of an index). Unloading an index or a shard in this way will delete it and make it unavailable for query.
If you unload or delete a shard from the Solr Admin Console, ensure you restart the Solr server and restore your indexes so that Alfresco can work properly.
Indexing JMX client
You can use a JMX client, such as JConsole, for monitoring the status of all the available indexes, shards and its instances, and other related information.
The JMX view of all the instancess, shards, and indexes that stick together is displayed at the MBeans > Alfresco > FlocAdmin > Attributes > Flocs node. The Flocs node displays a tabular view of all the indexes formed by shard instances by registering with any member of the Alfresco Content Services cluster.
-
Open a command console.
-
Enter the following command:
jconsole
The JConsole: New Connection window displays.
-
Double-click on the Java process.
For Tomcat, the Java process is usually labelled as
org.apache.catalina.startup.Bootstrap start.The Java Monitoring & Management window displays.
-
Select the MBeans tab.
The available managed beans display in JConsole.
-
Navigate to Alfresco > FlocAdmin.
The Attributes and Operations display below it in the tree.
-
Select Attributes.
-
Floc/Index level information
All instances that stick together to form an index have the same value for the following settings:
Attribute name Description Is configurable or displays state activeTrackingMode Specifies if the instances for the index are all SLAVE,MASTER, orMIXED. Note: TheSLAVEandMIXEDinstances are not supported for a sharded installation.State hasContent If the index contains content, the value of this attribute is true, otherwisefalse.Configurable lowReplicaShards Specifies a comma separated list of shards that have less than maxReplicas.State maxReplicas Specifies the number of instances for the shard which has the maximum number of instances, for example 1.State maxRepoChangeSetId Specifies the maximum changeset id in the repository, for example 5029.State maxRepoTxId Specifies the maximum transaction id in the repository, for example 16903.State maxTransactions Specifies the maximum number of transactions in any instance. State minReplicas Specifies the number of instances for the shard which has the minimum number of instances, for example 1.State missingShards Specifies a comma separated list of shards with no instances. State numberOfShards Specifies the total number of shards, for example 2.Configurable shardMethod Specifies how the nodes and ACLs are split into shards, for example MOD_ACL_ID.Configurable shards Click to display tabular data for each shard, for example Shards.Displays details stores Specifies the stores that are indexed, for example workspace://SpacesStore.Configurable template Specifies the name of the template used to create each core with common configuration, for example rerank.Configurable -
Shard level information
You can navigate through each shard using the tabular navigation.
Attribute name Description Is configurable or displays state? # Specifies the shard number, for example 0.Configurable activeCount Specifies the number of instances that are currently able to answer queries, for example 1.State activeTrackingMode Specifies if the instances for the shard are all SLAVE,MASTER, orMIXED. Note: TheSLAVEandMIXEDinstances are not supported for a sharded installation.State laggingCount Specifies the number of instances that are currently unable to answer queries because they are too far behind, for example ‘0’. State maxTransactionsRemaining Specifies the maximum number of transactions left to index for any shard instance, for example 1.State maxTxId Specifies the maximum number of transaction id indexes by any instance, for example 16903.State silentCount Specifies the number of instances that are no longer tracking. State replicas Provide details for each instance in the shard, for example Instances.Displays details -
Instance level information
Attribute name Description Displays location or state? baseUrl Specifies the URL to access the instance, for example /solr4/alfresco-0/Location host Specifies the host where the instance is located, for example 172.31.42.83.Location port Specifies the port on the host where the instance is located. Location lastIndexedChangeSetCommitTime Specifies the date and time of the last indexed changeset, for example Wed Oct 28 12:09:41 GMT 2015.State lastIndexedChangeSetId Specifies the last indexed changeset id in the repository, for example 5029.State lastIndexedTxCommitTime Specifies the date and time of the last indexed transaction, for example Wed Oct 28 12:30:33 GMT 2015.State lastIndexedTxId Specifies the transaction id of the last indexed transaction, for example 16903.State lastUpdated Specifies when the instance was last updated, for example Wed Oct 28 13:31:30 GMT 2015.State state Specifies if the instance state is ACTIVE,SILENT, orLAGGING.State trackingMode Specifies if the tracking is performed by the master. State transactionsRemaining Specifies the number of transactions remaining to be indexed, for example 5.State
-
-
Select Operations.
removeAgedOutShardsremoves all the shards which are too far behind and no longer tracking or are unresponsive.removeAllremoves all the shards that have registered and starts from clean. -
If you are using a sharded installation, go to MBeans > Alfresco > Configuration > Search > managed > solr6 > Attributes and set the number of filters using the
solr.defaultShardedFacetLimitproperty.solr.defaultShardedFacetLimit=20 -
If you are using a non-sharded installation, go to MBeans > Alfresco > Configuration > Search > managed > solr6 > Attributes and set the number of filters using the
solr.defaultUnshardedFacetLimitproperty.solr.defaultUnshardedFacetLimit=100
Finding shards at query time
Use a JMX client to find shards at query time.
-
In JConsole, go to MBeans > Alfresco > Configuration > Search > managed > solr6 > Attributes.
All the Solr attributes are listed on this page.
-
Set the following properties:
solr6.alfresco.numShards=10 solr6.archive.numShards=10 -
In JConsole, go to MBeans > Alfresco > Configuration > Search > managed > solr6 > solr6.store.mappings.
-
Set
numShardsforsolrMappingAlfrescoandsolrMappingArchive.-
Go to solrMappingAlfresco > Attributes > numShards and set the value of
numShards.numShards=10 -
Go to solrMappingArchive > Attributes > numShards and set the value of
numShards.numShards=10
-
Reindex documents by query
You can selectively reindex a small subset of the index based on a query. This enables a limited rebuild of the index.
Example 1: To reindex people after changing the first name and last name tokenisation, use the following single-threaded query:
http://localhost:8983/solr/admin/cores?action=reindex&query=TYPE:"cm:person"
Example 2: To reindex jobs that failed or threw an exception when indexing, use the following query:
http://localhost:8983/solr/admin/cores?action=reindex&query=EXCEPTIONMESSAGE:*
You must first run the query to see how many nodes are affected. If the result is large, you can add paging as part of the query in order to reindex in smaller batches.
<query> AND created:"2015-08"
Query based reindexing is also useful when changing the property type, changing tokenisation, adding new properties to be treated as identifiers, or when reindexing synonyms.
In a sharded setup, the reindex query will have to be run on all the nodes. The query will run for all shards on any node.