There are five connectors that can be used to invoke different Amazon Web Services (AWS):
All Amazon connectors are displayed on the process diagram with their respective AWS logos.
Important: All AWS connectors require an AWS account with permission to access the features provided by Amazon. This account is separate to the Alfresco hosted environment and should be created and managed by customers.
Lambda
The INVOKE action is used by the Lambda connector to invoke Amazon Web Services (AWS) Lambda functions.
The input parameters to invoke a Lambda function are:
| Parameter | Type | Description |
|---|---|---|
| function | String | Required. The name of the Lambda function to invoke, for example lambda-2. |
| payload | JSON | Optional. The payload that will be passed to the Lambda function as a JSON object. |
The output parameters from invoking a Lambda function are:
| Parameter | Type | Description |
|---|---|---|
| lambdaPayload | JSON | Optional. The Lambda function results payload. |
| lambdaStatus | Integer | Optional. The Lambda function invocation status code. |
| lambdaLog | String | Optional. The log produced during the function invocation. |
Lambda configuration parameters
The configuration parameters for the Lambda connector are:
| Parameter | Description |
|---|---|
| AWS_LAMBDA_AWS_ACCESS_KEY | Required. The access key to authenticate against AWS. |
| AWS_LAMBDA_AWS_SECRET_KEY | Required. The secret key to authenticate against AWS. |
| AWS_LAMBDA_AWS_REGION | Required. The region of AWS to invoke the Lambda functions. |
Lambda errors
The possible errors that can be handled by the Lambda connector are:
| Error | Description |
|---|---|
| MISSING_INPUT | A mandatory input variable was not provided. |
| INVALID_INPUT | The input variable has an invalid type. |
| SERVICE_ERROR | The service encountered an internal error. |
| INVALID_REQUEST | The request body could not be parsed as JSON. |
| REQUEST_TOO_LARGE | The request payload exceeded the Invoke request body JSON input limit. |
| UNKNOWN_ERROR | Unexpected runtime error. |
| BAD_REQUEST | The server could not understand the request due to invalid syntax. |
| UNAUTHORIZED | The request has not been applied because it lacks valid authentication. |
| FORBIDDEN | The server understood the request but refuses to authorize it. |
| NOT_FOUND | The server could not find what was requested. |
| METHOD_NOT_ALLOWED | The request method is known by the server but is not supported. |
| NOT_ACCEPTABLE | The server cannot produce a response matching the list of acceptable values. |
| REQUEST_TIMEOUT | The server would like to shut down this unused connection. |
| CONFLICT | The request conflicts with current state of the server. |
| GONE | No longer available. |
| UNPROCESSABLE_ENTITY | The server understands the content type of the request entity, and the syntax of the request entity is correct, but it was unable to process the contained instructions. |
| LOCKED | The resource that is being accessed is locked. |
| FAILED_DEPENDENCY | The request failed due to failure of a previous request. |
| INTERNAL_SERVER_ERROR | The server has encountered a situation it doesn’t know how to handle. |
| NOT_IMPLEMENTED | The request method is not supported by the server and cannot be handled. |
| BAD_GATEWAY | The server got an invalid response. |
| SERVICE_UNAVAILABLE | The server is not ready to handle the request. |
| GATEWAY_TIMEOUT | The server is acting as a gateway and cannot get a response in time. |
Comprehend
The Comprehend connector provides a standard mechanism to extract entities and Personally identifiable information (PII) entities from text in your documents. The ENTITY action is used by the Comprehend connector to execute Amazon Comprehend natural language processing (NLP) services and identify and analyze text from specific plain text files. The Comprehend connector supports default entity recognition, custom entity recognition, and custom document classification.
Note: The Comprehend connector can only receive either files or text but not both at the same time.
The Comprehend connector can extract entities and PII from the following file formats:
text/plainapplication/x-tar/zip/vnd.ms-outlook/pdf (max size in bytes: 26214400)/msword/vnd.ms-project/vnd.ms-outlook/vnd.ms-powerpoint/vnd.visio/vnd.ms-excel/vnd.openxmlformats-officedocument.spreadsheetml.sheet/vnd.ms-word.document.macroenabled.12/vnd.openxmlformats-officedocument.wordprocessingml.document/vnd.ms-word.template.macroenabled.12/vnd.openxmlformats-officedocument.wordprocessingml.template/vnd.ms-powerpoint.template.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.template/vnd.ms-powerpoint.addin.macroenabled.12/vnd.ms-powerpoint.slideshow.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.slideshow/vnd.ms-powerpoint.presentation.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.presentation/vnd.ms-powerpoint.slide.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.slide/vnd.ms-excel.addin.macroenabled.12/vnd.ms-excel.sheet.binary.macroenabled.12/vnd.ms-excel.sheet.macroenabled.12/vnd.openxmlformats-officedocument.spreadsheetml.sheet/vnd.ms-excel.template.macroenabled.12/vnd.openxmlformats-officedocument.spreadsheetml.template/x-cpio/java-archive/x-netcdf/msword/vnd.ms-word.document.macroenabled.12/vnd.openxmlformats-officedocument.wordprocessingml.document/vnd.ms-word.template.macroenabled.12/vnd.openxmlformats-officedocument.wordprocessingml.template/x-gzip/x-hdftext/html/vnd.apple.keynote/vnd.ms-project/vnd.apple.numbers/vnd.oasis.opendocument.chart/vnd.oasis.opendocument.image/vnd.oasis.opendocument.text-master/vnd.oasis.opendocument.presentation/vnd.oasis.opendocument.spreadsheet/vnd.oasis.opendocument.text/ogg/vnd.oasis.opendocument.text-web/vnd.oasis.opendocument.presentation-template/vnd.oasis.opendocument.spreadsheet-template/vnd.oasis.opendocument.text-template/vnd.apple.pages/pdf "maxSourceSizeBytes": 26214400,/vnd.ms-powerpoint.template.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.template/vnd.ms-powerpoint.addin.macroenabled.12/vnd.ms-powerpoint.slideshow.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.slideshow/vnd.ms-powerpoint/vnd.ms-powerpoint.presentation.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.presentation/x-rar-compressed/rss+xml/rtf/vnd.ms-powerpoint.slide.macroenabled.12/vnd.openxmlformats-officedocument.presentationml.slide/vnd.sun.xml.writertext/xml/vnd.visio/xhtml+xml/vnd.ms-excel.addin.macroenabled.12/vnd.ms-excel/vnd.ms-excel.sheet.binary.macroenabled.12/vnd.ms-excel.sheet.macroenabled.12/vnd.openxmlformats-officedocument.spreadsheetml.sheet/vnd.ms-excel.template.macroenabled.12/vnd.openxmlformats-officedocument.spreadsheetml.template/x-compresstext/csv/msword
AWS Configuration
The Amazon Comprehend APIs that are called using the connector are:
- DetectDominantLanguage
- DetectEntities
- BatchDetectEntities
- StartEntitiesDetectionJob
- DescribeEntitiesDetectionJob
- DetectPiiEntities
- StartPiiEntitiesDetectionJob
- DescribePiiEntitiesDetectionJob
- StartDocumentClassificationJob
To perform these calls it uses the AWS Comprehend SDK. This requires IAM users with the correct permissions to be created. The easiest way to do this is to give an IAM user the AWS managed policy ComprehendFullAccess. If you want to be stricter with access rights see the list of all comprehend API permissions.
The Asynchronous calls also require the ability to read and write to an Amazon S3 bucket so the IAM user must have access to the configured bucket. As well as the IAM user accessing the data the Comprehend service itself requires access, for more see Role-Based Permissions Required for Asynchronous Operations .
To allow the library to use this IAM user when communicating with the Comprehend service an AWS access key and secret key must be available, for more see Using the Default Credential Provider Chain
DetectDominantLanguage
You need to supply the calls that detect the language of the text document that is going to be processed. To do this, the connector calls the DetectDominantLanguage API. The DetectDominantLanguage call only works on text smaller than a configurable limit, the default is 5000 bytes. The connector uses the first bytes/characters of the document to determine what language to use when making calls to AWS Comprehend to determine which language is being used.
The DetectDominantLanguage service currently supports a greater set of languages than the entity detection services. It does this by checking the returned language against a configurable list of available languages.
Note: Currently only EN and ES are supported by AWS entity detection. If the detected language is not in this list a configurable default language is used instead, which is EN by default.
Entities
The following are the different types of entities:
| Entity |
|---|
| DetectEntities |
| BatchDetectEntities |
| StartEntitiesDetectionJob |
| DescribeEntitiesDetectionJob |
Depending on the size of the input the connector will process it in a different a way.
The DetectEntities operation will be called if the supplied text file is smaller than a configurable limit, by default 5000 bytes. If the input file is larger than this then a different API must be used.
The BatchDetectEntitie is used if the file is larger than the DetectEntities limit although it also has a configurable limit, by default 125000 bytes. When you use the Batch API call the input file is split into chunks of less than the configurable limit, by default 5000 bytes.
The StartEntitiesDetectionJob and DescribeEntititesDetectionJob are used if the input file is larger than the BatchDetectEntities limit, by default 5000 bytes. Similar to the batch approach, the input file will be divided into a set of smaller files of a certain configured size. When dividing the original file, the engine ensures that it only includes full words and does not split on a non whitespace character.
The divided files are then uploaded to Amazon S3 using the same key prefix for all files. When all of them have been uploaded an asynchronous entity detection job is started. This is then followed by a polling process to check the status of the job until it finishes or the timeout is reached.
If the asynchronous job finishes successfully a compressed output file (output.tar.gz) with the result will be written by Amazon Comprehend. The file will be saved to the same bucket within a directory that is using the same key prefix. For more see Asynchronous Batch Processing
. The output file is downloaded from Amazon S3 and parsed into a BatchDetectEntitiesResult object. At the end of the process, all the resource files are cleaned, both locally and at Amazon S3.
PII Entities
| Entity |
|---|
| DetectPiiEntities |
| StartPiiEntitiesDetectionJob |
| DescribePiiEntitiesDetectionJob |
Depending on the size of the input the connector will process it in a different way.
The DetectPiiEntities operation will be called if the supplied text file is smaller than a configurable limit, by default 5000 bytes. If the input file is larger than this then a different API must be used.
The StartPiiEntitiesDetectionJob and DescribePiiEntitiesDetectionJob are used if the input file is larger than the AsynchDetectPIIEntities limit, by default 5000 bytes. The input file will be divided into a set of smaller files of a certain configured size. When dividing the original file, the engine ensures that it only includes full words and will not split on a non whitespace character.
The divided files are then uploaded to Amazon S3 using the same key prefix for all files. When all of them have been uploaded an asynchronous entity detection job is started. This is then followed by a polling process to check the status of the job until it finishes or the timeout is reached.
If the asynchronous job finishes successfully a compressed output file (output.tar.gz) with the result will be written by Amazon Comprehend. The file will be saved to the same bucket within a directory that is using the same key prefix. For more see Asynchronous Batch Processing
. The output file is downloaded from Amazon S3 and parsed into a BatchDetectPiiResult object. At the end of the process, all the resource files are cleaned, both locally and at Amazon S3.
The StartDocumentClassificationJob operation is always performed asynchronously. It requires a custom model and the classifier ARN must be provided. You can provide the custom classification ARN in two ways:
-
Use the
AWS_COMPREHEND_CUSTOM_CLASSIFICATION_ARNenvironment variable when deploying the application. -
Use the
customClassificationArninput variable in the connector action. If the variable is not provided theAWS_COMPREHEND_CUSTOM_CLASSIFICATION_ARNvalue is used.
BPMN Tasks Configuration
The following describes an example of how the text analysis connector is setup in AAE:
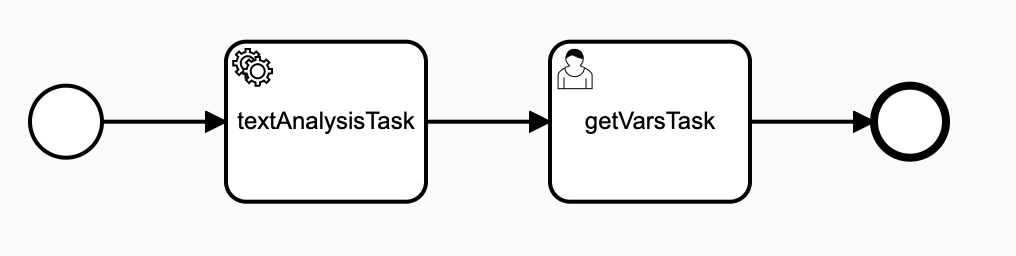
As part of the BPMN definition process, any service task responsible for triggering the text analysis comprehend.ENTITY has to be set as the value for its implementation attribute.
The following variables must be configured for the text analysis to function.
The input parameters of Entity detection are:
| Parameter | Type | Description |
|---|---|---|
| files | Array | Optional. The file to be analysed. If multiple files are passed, then only the first one will be analysed. |
| text | String | Optional. The Text to be analysed. If the files parameter is set, then this should be left blank. |
| maxEntities | Integer | Optional. The maximum number of entities that is returned. The parameter defaults to ${aws.comprehend.defaultMaxResults}. |
| confidenceLevel | Float | Optional. The minimum confidence level for a entity expressed by a float number between 0 and 1. The parameter defaults to ${aws.comprehend.defaultConfidence}. |
| timeout | Integer | Optional. The timeout for the remote call to the Comprehend service in milliseconds. The parameter defaults to ${aws.comprehend.asynchTimeout}. |
| customRecognizerArn | String | Optional. The custom recognizer ARN endpoint. If left blank, the Comprehend service will use the value given to the AWS_COMPREHEND_CUSTOM_RECOGNIZER_ARN environment variable. |
Note: The connector must receive either files or text but not both at the same time.
The following is an example of the POST body for the Activiti REST API http:////rb/v1/process-instances endpoint:
{
"processDefinitionKey": "TextAnalysisProcessTest",
"processInstanceName": "processTextAnalysisTest_Simple",
"businessKey": "MyBusinessKey",
"variables": {
"file" : [
{
"nodeId":"ad844189-9afb-4afb-965b-380db73022aa"
}
],
"maxEntities" : 50,
"confidenceLevel" : "0.95",
"timeout" : 10000
},
"payloadType":"StartProcessPayload"
}
In the business process definition, the text analysis service task called textAnalysisTask has the implementation attribute configured to use the connector.
<bpmn2:serviceTask id="ServiceTask_0j2v2yc" name="textAnalysisTask" implementation="comprehend.ENTITY">
<bpmn2:incoming>SequenceFlow_0kibr65</bpmn2:incoming>
<bpmn2:outgoing>SequenceFlow_1048knn</bpmn2:outgoing>
</bpmn2:serviceTask>
The input parameters of PII Entity detection are:
| Parameter | Type | Description |
|---|---|---|
| files | Array | Optional. The file to be analysed. If multiple files are passed, then only the first one will be analysed. |
| text | String | Optional. The Text to be analysed. If the files parameter is set, then this should be left blank. |
| maxEntities | Integer | Optional. The maximum number of entities that is returned. The parameter defaults to ${aws.comprehend.defaultMaxResults}. |
| confidenceLevel | Float | Optional. The minimum confidence level for a entity expressed by a float number between 0 and 1. The parameter defaults to ${aws.comprehend.defaultConfidence}. |
| timeout | Integer | Optional. The timeout for the remote call to the Comprehend service in milliseconds. The parameter defaults to ${aws.comprehend.asynchTimeout}. |
Note: The connector must receive either files or text but not both at the same time.
The input parameters of Document classification are:
| Parameter | Type | Description |
|---|---|---|
| files | Array | Optional. The file to be analysed. If multiple files are passed, then only the first one will be analysed. |
| text | String | Optional. The Text to be analysed. If the files parameter is set, then this should be left blank. |
| maxEntities | Integer | Optional. The maximum number of entities that is returned. The parameter defaults to ${aws.comprehend.defaultMaxResults}. |
| confidenceLevel | Float | Optional. The minimum confidence level for a entity expressed by a float number between 0 and 1. The parameter defaults to ${aws.comprehend.defaultConfidence}. |
| timeout | Integer | Optional. The timeout for the remote call to the Comprehend service in milliseconds. The parameter defaults to ${aws.comprehend.asynchTimeout}. |
| customClassificationArn | String | Optional. The custom recognizer ARN endpoint. If left blank, the Comprehend service will use the value given to the AWS_COMPREHEND_CUSTOM_CLASSIFICATION_ARN environment variable. Note: The AWS_COMPREHEND_CUSTOM_CLASSIFICATION_ARN environment variable does not have a default value. If it is being used then you must also set a value for it. |
Note: The connector must receive either files or text but not both at the same time.
The output parameters from the entity detection are:
| Parameter | Type | Description |
|---|---|---|
| awsResponse | JSON | Optional. The result of the analysis from the Comprehend service. |
| aisResponse | JSON | Optional. The result of the analysis in Alfresco Intelligence Service format. |
| entities | JSON | Optional. The result object containing the entities detected. |
The output parameters from the PII entity detection are:
| Parameter | Type | Description |
|---|---|---|
| awsResponse | JSON | Optional. The result of the analysis from the Comprehend service. |
| piiEntityTypes | JSON | Optional. The result object containing the PII entities detected. |
The output parameters from the Document classification are:
| Parameter | Type | Description |
|---|---|---|
| awsResponse | Object | Optional. The object that contains the original result of the text analysis performed by the Comprehend service. |
| documentClassificationClasses | Array | Optional. An array that contains the list of the different classes detected in the analysis. |
Comprehend configuration parameters
The configuration parameters for the Comprehend connector are:
| Parameter | Description |
|---|---|
| AWS_ACCESS_KEY_ID | Required. The access key to authenticate against AWS. |
| AWS_SECRET_KEY | Required. The secret key to authenticate against AWS. |
| AWS_REGION | Required. The region of AWS to use the Comprehend service. |
| AWS_S3_BUCKET | Required. The name of the S3 bucket to use. |
| AWS_COMPREHEND_ROLE_ARN | Required. The Amazon Resource Name for Comprehend to use. |
Comprehend errors
The possible errors that can be handled by the Comprehend connector are:
| Error | Description |
|---|---|
| MISSING_INPUT | A mandatory input variable was not provided. |
| INVALID_INPUT | The input variable has an invalid type. |
| INVALID_RESULT_FORMAT | The REST service result payload cannot be parsed. |
| TEXT_SIZE_LIMIT_EXCEEDED | The size of the input text exceeds the limit. |
| TOO_MANY_REQUEST | The request throughput limit was exceeded. |
| UNSUPPORTED_LANGUAGE | The language of the input text can’t be processed. |
| CLIENT_EXECUTION_TIMEOUT | The execution ends because of timeout. |
| UNKNOWN_ERROR | Unexpected runtime error. |
| BAD_REQUEST | The server could not understand the request due to invalid syntax. |
| UNAUTHORIZED | The request has not been applied because it lacks valid authentication. |
| FORBIDDEN | The server understood the request but refuses to authorize it. |
| NOT_FOUND | The server could not find what was requested. |
| METHOD_NOT_ALLOWED | The request method is known by the server but is not supported. |
| NOT_ACCEPTABLE | The server cannot produce a response matching the list of acceptable values. |
| REQUEST_TIMEOUT | The server would like to shut down this unused connection. |
| CONFLICT | The request conflicts with current state of the server. |
| GONE | No longer available. |
| UNPROCESSABLE_ENTITY | The server understands the content type of the request entity, and the syntax of the request entity is correct, but it was unable to process the contained instructions. |
| LOCKED | The resource that is being accessed is locked. |
| FAILED_DEPENDENCY | The request failed due to failure of a previous request. |
| INTERNAL_SERVER_ERROR | The server has encountered a situation it doesn’t know how to handle. |
| NOT_IMPLEMENTED | The request method is not supported by the server and cannot be handled. |
| BAD_GATEWAY | The server got an invalid response. |
| SERVICE_UNAVAILABLE | The server is not ready to handle the request. |
| GATEWAY_TIMEOUT | The server is acting as a gateway and cannot get a response in time. |
Limitations
PDF files larger than 26214400 bytes are not supported.
Rekognition
The LABEL action is used by the Rekognition connector to execute Amazon Rekognition services to identify and label the objects in JPEG and PNG files that are less than 15mb in size.
The Amazon Rekognition API that is called is the Detect Labels API.
Files between 5mb and 15mb are uploaded to an Amazon S3 bucket before processing. The IAM user configured to run the Rekognition service requires access to this bucket, the Rekognition service itself and to have the rekognition:DetectLabels permission.
The input parameters of the Rekognition connector are:
| Parameter | Type | Description |
|---|---|---|
| file | File | Required. A variable of type file to send for analysis. |
| mediaType | String | Optional. The media type of the file to be analyzed, for example /octect-stream. |
| maxLabels | Integer | Optional. The maximum number of labels to be return. The default value is 10. |
| confidenceLevel | String | Optional. The confidence level to use in the analysis between 0 and 1, for example 0.75. |
| timeout | Integer | Optional. The timeout period for calling the Rekognition service in milliseconds, for example 910000. |
The output parameters from the Rekognition analysis are:
| Parameter | Type | Description |
|---|---|---|
| awsResponse | JSON | Optional. The result of the analysis from the Rekognition service. |
| aisResponse | JSON | Optional. The result of the image analysis in Alfresco Intelligence Service format. |
| labels | JSON | Optional. The result object containing the labels detected. |
Rekognition configuration parameters
The configuration parameters for the Rekognition connector are:
| Parameter | Description |
|---|---|
| AWS_ACCESS_KEY_ID | Required. The access key to authenticate against AWS. |
| AWS_SECRET_KEY | Required. The secret key to authenticate against AWS. |
| AWS_REGION | Required. The region of AWS to use the Rekognition service in. |
| AWS_S3_BUCKET | Required. The name of the S3 bucket to use. |
Rekognition errors
The possible errors that can be handled by the Rekognition connector are:
| Error | Description |
|---|---|
| MISSING_INPUT | A mandatory input variable was not provided. |
| INVALID_INPUT | The input variable has an invalid type. |
| INVALID_RESULT_FORMAT | The REST service result payload cannot be parsed. |
| PROVISIONED_THROUGHPUT_EXCEEDED | The number of requests exceeded your throughput limit. |
| ACCESS_DENIED | The user is not authorized to perform the action. |
| IMAGE_TOO_LARGE | The input image size exceeds the allowed limit. |
| INVALID_IMAGE_FORMAT | The provided image format is not supported. |
| LIMIT_EXCEEDED | The service limit was exceeded. |
| THROTTLING_ERROR | The service is temporarily unable to process the request. |
| UNKNOWN_ERROR | Unexpected runtime error. |
| BAD_REQUEST | The server could not understand the request due to invalid syntax. |
| UNAUTHORIZED | The request has not been applied because it lacks valid authentication. |
| FORBIDDEN | The server understood the request but refuses to authorize it. |
| NOT_FOUND | The server could not find what was requested. |
| METHOD_NOT_ALLOWED | The request method is known by the server but is not supported. |
| NOT_ACCEPTABLE | The server cannot produce a response matching the list of acceptable values. |
| REQUEST_TIMEOUT | The server would like to shut down this unused connection. |
| CONFLICT | The request conflicts with current state of the server. |
| GONE | No longer available. |
| UNPROCESSABLE_ENTITY | The server understands the content type of the request entity, and the syntax of the request entity is correct, but it was unable to process the contained instructions. |
| LOCKED | The resource that is being accessed is locked. |
| FAILED_DEPENDENCY | The request failed due to failure of a previous request. |
| INTERNAL_SERVER_ERROR | The server has encountered a situation it doesn’t know how to handle. |
| NOT_IMPLEMENTED | The request method is not supported by the server and cannot be handled. |
| BAD_GATEWAY | The server got an invalid response. |
| SERVICE_UNAVAILABLE | The server is not ready to handle the request. |
| GATEWAY_TIMEOUT | The server is acting as a gateway and cannot get a response in time. |
Textract
The EXTRACT action is used by the Textract connector to execute Amazon Textract to extract text and metadata from JPEG and PNG files that are less than 5mb in size.
The Amazon Textract APIs called are the Detect Document Text API which joins all LINE block objects with a line separator between them and the Analyze Document API with FORM and TABLES analysis.
The IAM user configured to run the Textract services needs to have the textract:DetectDocumentText and textract:AnalyzeDocument permissions.
The input parameters of the Textract connector are:
| Parameter | Type | Description |
|---|---|---|
| file | File | Required. A variable of type file to send for extraction. |
| outputFormat | String | Optional. The format of the output file. Possible values are JSON and TXT. The default value is JSON. |
| confidenceLevel | String | Optional. The confidence level to use in the analysis between 0 and 1, for example 0.75. |
| timeout | Integer | Optional. The timeout period for calling the Textract service in milliseconds, for example 910000. |
The output parameters from the Textract analysis are:
| Parameter | Type | Description |
|---|---|---|
| awsResult | JSON | Optional. The result of the analysis from the Textract service. |
Textract configuration parameters
The configuration parameters for the Textract connector are:
| Parameter | Description |
|---|---|
| AWS_ACCESS_KEY_ID | Required. The access key to authenticate against AWS. |
| AWS_SECRET_KEY | Required. The secret key to authenticate against AWS. |
| AWS_REGION | Required. The region of AWS to use the Textract service. |
| AWS_S3_BUCKET | Required. The name of the S3 bucket to use. |
Textract errors
The possible errors that can be handled by the Textract connector are:
| Error | Description |
|---|---|
| MISSING_INPUT | A mandatory input variable was not provided. |
| INVALID_INPUT | The input variable has an invalid type. |
| INVALID_RESULT_FORMAT | The REST service result payload cannot be parsed. |
| PROVISIONED_THROUGHPUT_EXCEEDED | The number of requests exceeded your throughput limit. |
| ACCESS_DENIED | The user is not authorized to perform the action. |
| IMAGE_TOO_LARGE | The input image size exceeds the allowed limit. |
| INVALID_IMAGE_FORMAT | The provided image format is not supported. |
| LIMIT_EXCEEDED | The service limit was exceeded. |
| THROTTLING_ERROR | The service is temporarily unable to process the request. |
| UNKNOWN_ERROR | Unexpected runtime error. |
| BAD_REQUEST | The server could not understand the request due to invalid syntax. |
| UNAUTHORIZED | The request has not been applied because it lacks valid authentication. |
| FORBIDDEN | The server understood the request but refuses to authorize it. |
| NOT_FOUND | The server could not find what was requested. |
| METHOD_NOT_ALLOWED | The request method is known by the server but is not supported. |
| NOT_ACCEPTABLE | The server cannot produce a response matching the list of acceptable values. |
| REQUEST_TIMEOUT | The server would like to shut down this unused connection. |
| CONFLICT | The request conflicts with current state of the server. |
| GONE | No longer available. |
| UNPROCESSABLE_ENTITY | The server understands the content type of the request entity, and the syntax of the request entity is correct, but it was unable to process the contained instructions. |
| LOCKED | The resource that is being accessed is locked. |
| FAILED_DEPENDENCY | The request failed due to failure of a previous request. |
| INTERNAL_SERVER_ERROR | The server has encountered a situation it doesn’t know how to handle. |
| NOT_IMPLEMENTED | The request method is not supported by the server and cannot be handled. |
| BAD_GATEWAY | The server got an invalid response. |
| SERVICE_UNAVAILABLE | The server is not ready to handle the request. |
| GATEWAY_TIMEOUT | The server is acting as a gateway and cannot get a response in time. |
Transcribe
The transcribe connector provides a standard mechanism to obtain speech to text information from audio and video files using Amazon Transcribe.
Installation
The connector is a Spring Boot application that is included as a separate service of your AAE deployment.
AWS Configuration
Alfresco recommends you access AWS using AWS Identity and Access Management (IAM). To use IAM to access AWS, create an IAM user, add the user to an IAM group with administrative permissions, and then grant administrative permissions to the IAM user. You can then access AWS using a special URL and the IAM user’s credentials.
BPMN Tasks Configuration
As part of BPMN definition process, any service task responsible for triggering speech to text needs to set transcribe.TRANSCRIBE as the value for its implementation attribute.
In addition to the above configuration, these variables are required to perform the audio analysis:
The input parameters of the transcribe connector are:
| Parameter | Type | Description |
|---|---|---|
| file | Array | Required. File to be transcribed. If multiple files are passed, only the first one will be processed. |
| timeout | Integer | Optional. Timeout for the remote call to transcribe service in milliseconds. The default is ${aws.transcribe.asynchTimeout}. |
| generateWebVTT | Boolean | Optional The output webVTT is only populated if generateWebVTT is set to true. |
The output parameters of the Transcribe connector are:
| Parameter | Type | Description |
|---|---|---|
| awsResult | JSON | Optional. Result of the AWS Transcribe speech to text process. |
| transcription | String | Required. Transcription result. |
| webVTT | JSON | Optional Subtitles result in Web Video Text Tracks format. |
Transcribe configuration parameters
The configuration parameters for the Transcribe connector are:
| Parameter | Description |
|---|---|
| AWS_ACCESS_KEY_ID | Required. The access key to authenticate against AWS. |
| AWS_SECRET_KEY | Required. The secret key to authenticate against AWS. |
| AWS_REGION | Required. The region of AWS to use the Textract service. |
| AWS_S3_BUCKET | Required. The name of the S3 bucket to use. |
| AWS_TRANSCRIBE_LANGUAGES | List of comma separated languages that are spoken in the audio/video file. |
Transcribe errors
The possible errors that can be handled by the Transcribe connector are:
| Error | Description |
|---|---|
| MISSING_INPUT | A mandatory input variable was not provided. |
| INVALID_INPUT | The input variable has an invalid type. |
| INVALID_RESULT_FORMAT | The REST service result payload cannot be parsed. |
| LIMIT_EXCEEDED | The service limit was exceeded. |
| ACCESS_DENIED | The user is not authorized to perform the action. |
| INTERNAL_FAILURE | An internal Amazon Lex error occurred. |
| UNKNOWN_ERROR | Unexpected runtime error. |
| BAD_REQUEST | The server could not understand the request due to invalid syntax. |
| UNAUTHORIZED | The request has not been applied because it lacks valid authentication. |
| FORBIDDEN | The server understood the request but refused to authorize it. |
| NOT_FOUND | The server could not find what was requested. |
| METHOD_NOT_ALLOWED | The request method is known by the server but is not supported. |
| NOT_ACCEPTABLE | The server cannot produce a response matching the list of acceptable values. |
| REQUEST_TIMEOUT | The server is requesting to shut down this unused connection. |
| CONFLICT | The request conflicts with the current state of the server. |
| GONE | No longer available. |
| UNPROCESSABLE_ENTITY | The server understands the content type of the request entity, and the syntax of the request entity is correct, but it was unable to process the contained instructions. |
| LOCKED | The resource that is being accessed is locked. |
| FAILED_DEPENDENCY | The request failed due to failure of a previous request. |
| INTERNAL_SERVER_ERROR | The server has encountered a situation and does not know how to handle it. |
| NOT_IMPLEMENTED | The request method is not supported by the server and cannot be handled. |
| BAD_GATEWAY | The server got an invalid response. |
| SERVICE_UNAVAILABLE | The server is not ready to handle the request. |
| GATEWAY_TIMEOUT | The server is acting as a gateway and cannot get a response in time. |
Limitations
Minimum confidence is not currently supported. The confidence is however included as part of the response.